Chainer Hands-on: Introduction To Train Deep Learning Model in Python¶
Goal¶
Play with neural networks using Chainer in image recognition.
Lessons to be learned¶
Attendees will learn the following features of Chainer.
- Easy debug
- CPU/GPU-compatible array manipulation
Agenda¶
Section 1. MNIST Classification by Perceptron¶
Simple neural networks to classify hand-written digit images
- Defining and training multi-layer perceptron
- Evaluating and visualizing result
- Model improvement and debugging
Section 2. Inside Chainer¶
Summary of features, class structures and implementations
- NumPy and CuPy
- Variable and Function
- Link and Chain
- Define-by-Run
Note¶
We assume that Chainer 1.20.0.1 is installed on a CUDA-7.0-enabled environment for this jupyter notebook.
[1]:
## Install Chainer and CuPy!
!curl https://colab.chainer.org/install | sh -
Reading package lists... Done
Building dependency tree
Reading state information... Done
libcusparse8.0 is already the newest version (8.0.61-1).
libnvrtc8.0 is already the newest version (8.0.61-1).
libnvtoolsext1 is already the newest version (8.0.61-1).
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
Requirement already satisfied: cupy-cuda80 in /usr/local/lib/python3.6/dist-packages (4.3.0)
Requirement already satisfied: chainer in /usr/local/lib/python3.6/dist-packages (4.3.1)
Requirement already satisfied: numpy>=1.9.0 in /usr/local/lib/python3.6/dist-packages (from cupy-cuda80) (1.14.5)
Requirement already satisfied: fastrlock>=0.3 in /usr/local/lib/python3.6/dist-packages (from cupy-cuda80) (0.3)
Requirement already satisfied: six>=1.9.0 in /usr/local/lib/python3.6/dist-packages (from cupy-cuda80) (1.11.0)
Requirement already satisfied: filelock in /usr/local/lib/python3.6/dist-packages (from chainer) (3.0.4)
Requirement already satisfied: protobuf>=3.0.0 in /usr/local/lib/python3.6/dist-packages (from chainer) (3.6.0)
Requirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.0.0->chainer) (39.1.0)
Preparation: Chainer import¶
First, import Chainer and related modules. CuPy will be introduced later.
[2]:
## Import Chainer
from chainer import Chain, Variable, optimizers, serializers, datasets, training
from chainer.training import extensions
import chainer.functions as F
import chainer.links as L
import chainer
## Import NumPy and CuPy
import numpy as np
import cupy as cp
## Utilities
import time
import math
print('Chainer version: ', chainer.__version__)
Chainer version: 4.3.1
Section 1. MNIST Classification by Perceptron¶
MNIST is a benchmark classification dataset in machine learning. It contains 70,000 hand-written digit images. Labels (0-9) are also provided (10-class classification problem). The task is to predict which digit given images belongs to.
Each sample is represented as 28x28 gray scale image (784 dimensional vector)
As the most simple neural network model, we use a multi-layer perceptron of size 2 (MLP2). It consists of input, output, and one hidden unit between them. They are connected with linear layers (fully-connected layers), which contain weight matrix and bias term, respectively. The activation function for the hidden unit is hyperbolic tangent (tanh).
The following class implements MLP2. Note that only the type and size of each layer is defined in __init__ method. The actual forward computation is directly written in a separate __call__ method. On the other hand, there is no explicit definition of backward computation, since Chainer remembers the computational graph in forward computation and backward computation can be done along it (described in Section 2).
[ ]:
## 2-layer Multi-Layer Perceptron (MLP)
class MLP2(Chain):
# Initialization of layers
def __init__(self):
super(MLP2, self).__init__(
l1=L.Linear(784, 100), # From 784-dimensional input to hidden unit with 100 nodes
l2=L.Linear(100, 10), # From hidden unit with 100 nodes to output unit with 10 nodes (10 classes)
)
# Forward computation by __call__
def __call__(self, x):
h1 = F.tanh(self.l1(x)) # Forward from x to h1 through activation with tanh function
y = self.l2(h1) # Forward from h1to y
return y
MNIST dataset can be loaded into main memory by chainer.datasets.get_mnist().
Following the standard problem setting of MNIST, we divide 70,000 samples into the training image-label pairs, train of size 60,000, and the testing pairs test, of size 10,000.
[4]:
train, test = chainer.datasets.get_mnist()
print('Train:', len(train))
print('Test:', len(test))
Train: 60000
Test: 10000
These variables will be used throughout the experiments.
[ ]:
batchsize=100
Experiment 1.1 - CPU-based training of MLP2¶
As the initial setting, we use NumPy for CPU-based execution. Number of epochs (how many times each training sample will be used) is set to 2.
[ ]:
enable_cupy = False # No CuPy (Use NumPy)
n_epoch=2 # Only 2 epochs
Definition: method for MNIST train and test¶
The following train_and_test() actually run the experiments by using Trainer that was introduced from Chainer v1.11.0. It contains the last 3 parts of the standard ML workflow below.
Optimizer will be used during the model training to update the model parameters (weight matrix and bias term for linear layer) through back propagation. Chainer supports most of the widely-used optimizers (SGD, AdaGrad, RMSProp, Adam, etc…). Here we use SGD. L.Classifier is a wrapper to build a classification model using a neural network, which is MLP2 in this setting. The default loss for L.Classifier is softmax cross entropy.
[ ]:
def train_and_test():
training_start = time.clock()
log_trigger = 600, 'iteration'
device = -1
if enable_cupy:
model.to_gpu()
chainer.cuda.get_device(0).use()
device = 0
optimizer = optimizers.SGD()
optimizer.setup(classifier_model)
train_iter = chainer.iterators.SerialIterator(train, batchsize)
test_iter = chainer.iterators.SerialIterator(test, batchsize, repeat=False, shuffle=False)
updater = training.StandardUpdater(train_iter, optimizer, device=device)
trainer = training.Trainer(updater, (n_epoch, 'epoch'), out='out')
trainer.extend(extensions.dump_graph('main/loss'))
trainer.extend(extensions.Evaluator(test_iter, classifier_model, device=device))
trainer.extend(extensions.LogReport(trigger=log_trigger))
trainer.extend(extensions.PrintReport(
['epoch', 'iteration', 'main/loss', 'validation/main/loss',
'main/accuracy', 'validation/main/accuracy']), trigger=log_trigger)
trainer.run()
elapsed_time = time.clock() - training_start
print('Elapsed time: %3.3f' % elapsed_time)
Execution: wait until test finishes¶
Let’s run the experiment and get the first result. It takes 30 seconds or so.
[8]:
model = MLP2() # MLP2 model
classifier_model = L.Classifier(model)
train_and_test() # May take 30 sec or more
epoch iteration main/loss validation/main/loss main/accuracy validation/main/accuracy
1 600 1.12293 0.6524 0.752617 0.8582
2 1200 0.566502 0.473245 0.86225 0.882
Elapsed time: 15.236
Evaluation: see the 1st result¶
The validation/main/accuracy should be less than 0.90. This is not bad, but can be improved. Later we will try other settings.
Preparation: import visualization tools¶
We use matplotlib to display computational graphs and MNIST images.
[9]:
## Import utility and visualization tools
!apt-get install graphviz
!pip install pydot
import pydot
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from IPython.display import Image, display
import chainer.computational_graph as cg
Reading package lists... Done
Building dependency tree
Reading state information... Done
graphviz is already the newest version (2.38.0-16ubuntu2).
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
Requirement already satisfied: pydot in /usr/local/lib/python3.6/dist-packages (1.2.4)
Requirement already satisfied: pyparsing>=2.1.4 in /usr/local/lib/python3.6/dist-packages (from pydot) (2.2.0)
Definition: method for visualizing computational graph¶
Chainer can export the computational graph from input to the loss function.
[ ]:
def display_graph():
graph = pydot.graph_from_dot_file('out/cg.dot') # load from .dot file
graph[0].write_png('graph.png')
img = Image('graph.png', width=600, height=600)
display(img)
Execution: visualize the computational graph of MLP2¶
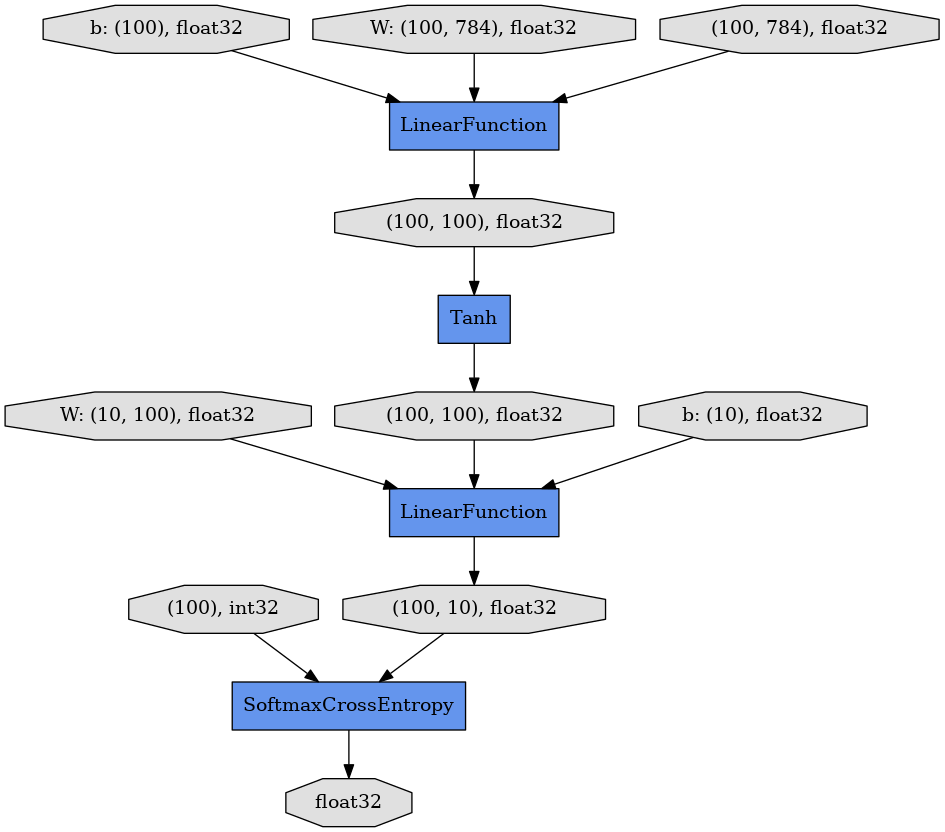
By running display_graph(), a directed graph will be shown. Three ellipsoids on top correspond to the input 100 images with 784 dimensions, weight matrix of size 100x784, and the bias term vector of length 100 for a linear layer.
The intermediate hidden unit with 100 nodes will be transferred to the next linear layer through a tanh activation function. The final 100 vectors for 10 classes are compared to the answers of int32 with SoftmaxCrossEntropy loss function. The loss value is given as a float32 value.
After building this graph, the backpropagation can work from the loss back to the input to update the model parameters (the weight matrices and bias terms of two LinearFunction).
[11]:
display_graph()
Definition: method for plotting images with predictions¶
“Answer’” is the ground truth given in the dataset, and “Predict:” gives the prediction by the current model.
[ ]:
def plot_examples():
%matplotlib inline
plt.figure(figsize=(12,50))
if enable_cupy:
model.to_cpu()
for i in range(45, 105):
x = Variable(np.asarray([test[i][0]])) # test data
t = Variable(np.asarray([test[i][1]])) # labels
y = model(x)
prediction = y.data.argmax(axis=1)
example = (test[i][0] * 255).astype(np.int32).reshape(28, 28)
plt.subplot(20, 5, i - 44)
plt.imshow(example, cmap='gray')
plt.title("No.{0} / Answer:{1}, Predict:{2}".format(i, t.data[0], prediction[0]))
plt.axis("off")
plt.tight_layout()
Execution: see some of examples are misclassified¶
Though most of the samples are correctly classified, there can be some mistakes. For example, No. 46 on the first row might be classified as ‘3’, though it looks ‘1’ to humans. The current model may also misclassify No.54 on the second row as ‘2’, which is a strange ‘6’.
[13]:
plot_examples()

Experiment 1.2 - Increase number of epochs¶
To improve the test accuracy, try to simply increase the number of epochs. Other conditions remain the same.
[ ]:
enable_cupy = False
n_epoch=5 # Increased from 2 to 5
Execution: run the new experiment with 5 epochs¶
Definitely it will take longer time.
[15]:
model = MLP2()
classifier_model = L.Classifier(model)
train_and_test()
epoch iteration main/loss validation/main/loss main/accuracy validation/main/accuracy
1 600 1.13003 0.65561 0.748433 0.8549
2 1200 0.565097 0.473293 0.864067 0.8843
3 1800 0.452602 0.405271 0.882583 0.8944
4 2400 0.401363 0.368402 0.891067 0.9006
5 3000 0.370984 0.344863 0.89725 0.9049
Elapsed time: 33.086
Evaluation: find that the accuracy becomes higher¶
The loss is smaller and the validation/main/accuracy is higher (0.90+) than the previous experiment.
Execution: find which mistakes have been removed¶
No.46 and/or No.54 can be correctly classified this time
[16]:
plot_examples()

Experiment 1.3 - Enable GPU computation with CuPy¶
Though adding more epochs can lead to higher accuracy, 5 epochs already takes more than one minute. In this case, we try to make it faster by enabling CuPy to use GPU.
[ ]:
enable_cupy = True # Now use CuPy
n_epoch=5
Execution: train the same model using GPU¶
The speed of training is clearly different.
[18]:
model = MLP2()
classifier_model = L.Classifier(model)
train_and_test()
epoch iteration main/loss validation/main/loss main/accuracy validation/main/accuracy
1 600 1.10894 0.640712 0.752166 0.8585
2 1200 0.558549 0.463849 0.865416 0.8837
3 1800 0.449113 0.398115 0.884584 0.8942
4 2400 0.399297 0.362251 0.893501 0.9024
5 3000 0.369314 0.339284 0.8993 0.9085
Elapsed time: 17.687
Evaluation: compare the training time¶
GPU-enabled training should be 5+ times faster than CPU.
Experiment 1.4 - Add one more layer¶
Then we use a different MLP with one more layer.
Definition: MLP with 3 layers¶
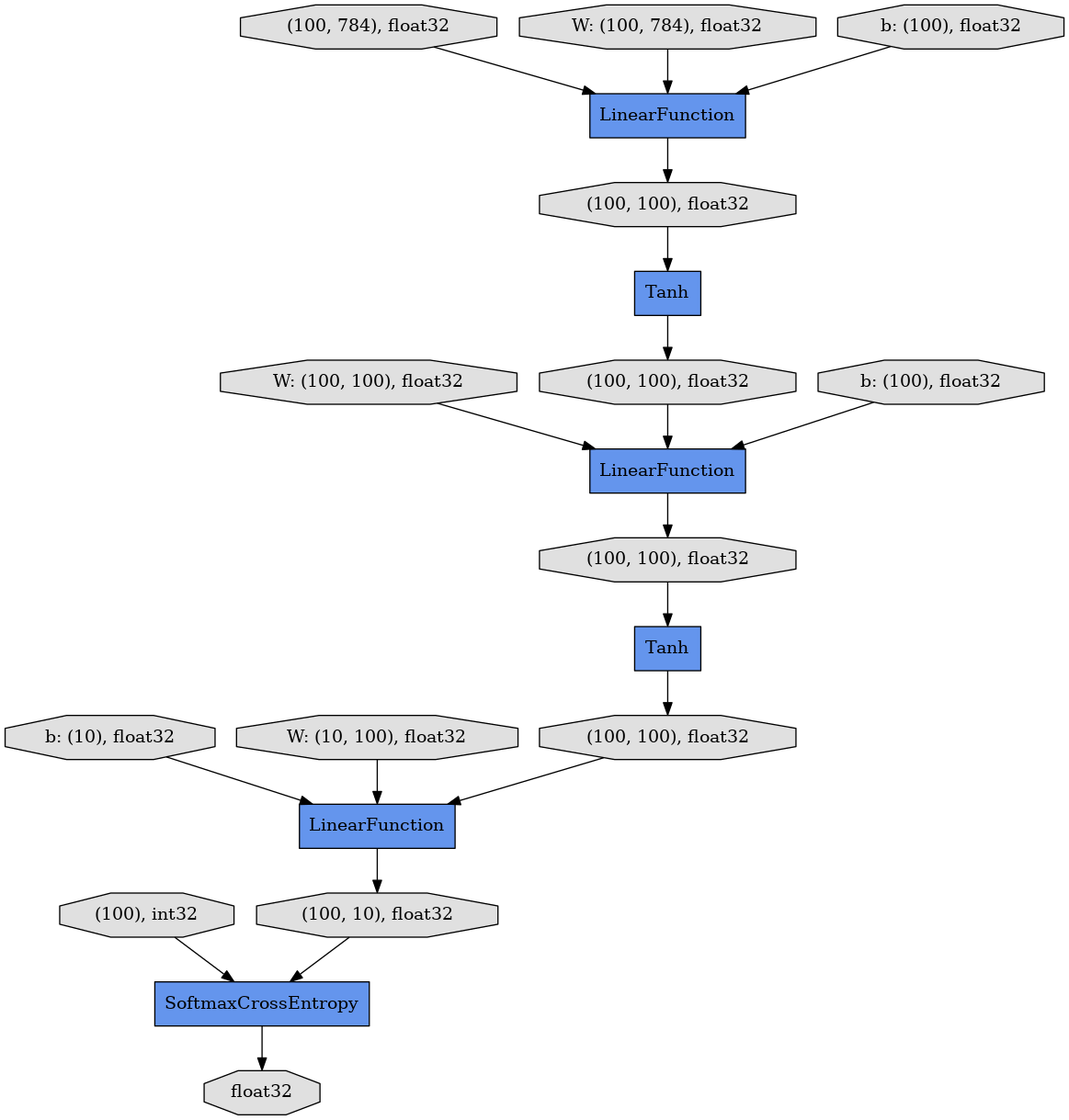
MLP3 has two hidden units of same size (100 nodes), which are also connected with additional L.Linear. The forward computation is almost the same with MLP2 to use tanh as activation functions.
[ ]:
## 3-layer multi-Layer Perceptron (MLP)
class MLP3(Chain):
def __init__(self):
super(MLP3, self).__init__(
l1=L.Linear(784, 100),
l2=L.Linear(100, 100), # Additional layer
l3=L.Linear(100, 10)
)
def __call__(self, x):
h1 = F.tanh(self.l1(x)) # Hidden unit 1
h2 = F.tanh(self.l2(h1)) # Hidden unit 2
y = self.l3(h2)
return y
Preparation: create MLP3-based classifier model¶
[ ]:
enable_cupy = True
n_epoch=5
Execution: train new MLP3-based model¶
[21]:
model = MLP3() # Use MLP3 instead of MLP2
classifier_model = L.Classifier(model)
train_and_test()
epoch iteration main/loss validation/main/loss main/accuracy validation/main/accuracy
1 600 1.06588 0.590563 0.749349 0.8589
2 1200 0.506428 0.421322 0.87035 0.8923
3 1800 0.402706 0.360067 0.89145 0.9022
4 2400 0.356675 0.328675 0.900918 0.9083
5 3000 0.329147 0.306729 0.906951 0.9128
Elapsed time: 20.396
Evaluation: compare the accuracy of MLP3 with MLP2¶
MLP3 can achieve smaller loss and higher accuracy thanks to its higher expressiveness. On the other hand, the computation time slightly increases for handling more parameters.
Execution: see the computational graph with 3 layers¶
It contains 3 LinearFunction and 2 Tanh activations.
[22]:
display_graph()
Execution: can you find any misclassified samples?¶
MLP3 is good enough to predict the labels of most of the samples.
[23]:
plot_examples()

Chainer’s feature - (1) Easy debug¶
Debugging complex neural networks is hard because runtime errors of other frameworks usually do not directly tell which part of model definition or implementation is wrong. However, Chainer supports type check in forward computation, so that debugging neural networks can be done just like debugging programs.
Definition: an enbugged version of MLP¶
In MLP3Wrong, three bugs were introduced into MLP3. Let’s find them during the execution and correct one by one later.
[ ]:
## Find three bugs in this model definition
class MLP3Wrong(Chain):
def __init__(self):
super(MLP3Wrong, self).__init__(
l1=L.Linear(748, 100),
l2=L.Linear(100, 100),
l3=L.Linear(100, 10)
)
def __call__(self, x):
h1 = F.tanh(self.l1(x))
h2 = F.tanh(self.l2(x))
y = self.l3(h3)
return y
enable_cupy = True
n_epoch=5
Execution: find errors by reading stack trace¶
In the forward computation, the stack trace points out where the errors actually occur. This is done by the Define-by-Run approach of Chainer, in which the computational graph is directly constructed during forward computation.
If you finish correcting three bugs, MLP3Wrong must be exactly the same with the definition of MLP3.
[25]:
model = MLP3Wrong() # MLP3Wrong
classifier_model = L.Classifier(model)
train_and_test()
Exception in main training loop:
Invalid operation is performed in: LinearFunction (Forward)
Expect: in_types[0].shape[1] == in_types[1].shape[1]
Actual: 784 != 748
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/chainer/training/trainer.py", line 306, in run
update()
File "/usr/local/lib/python3.6/dist-packages/chainer/training/updaters/standard_updater.py", line 149, in update
self.update_core()
File "/usr/local/lib/python3.6/dist-packages/chainer/training/updaters/standard_updater.py", line 160, in update_core
optimizer.update(loss_func, *in_arrays)
File "/usr/local/lib/python3.6/dist-packages/chainer/optimizer.py", line 650, in update
loss = lossfun(*args, **kwds)
File "/usr/local/lib/python3.6/dist-packages/chainer/links/model/classifier.py", line 134, in __call__
self.y = self.predictor(*args, **kwargs)
File "<ipython-input-24-532380536ccf>", line 11, in __call__
h1 = F.tanh(self.l1(x))
File "/usr/local/lib/python3.6/dist-packages/chainer/links/connection/linear.py", line 134, in __call__
return linear.linear(x, self.W, self.b)
File "/usr/local/lib/python3.6/dist-packages/chainer/functions/connection/linear.py", line 234, in linear
y, = LinearFunction().apply(args)
File "/usr/local/lib/python3.6/dist-packages/chainer/function_node.py", line 243, in apply
self._check_data_type_forward(in_data)
File "/usr/local/lib/python3.6/dist-packages/chainer/function_node.py", line 328, in _check_data_type_forward
self.check_type_forward(in_type)
File "/usr/local/lib/python3.6/dist-packages/chainer/functions/connection/linear.py", line 23, in check_type_forward
x_type.shape[1] == w_type.shape[1],
File "/usr/local/lib/python3.6/dist-packages/chainer/utils/type_check.py", line 524, in expect
expr.expect()
File "/usr/local/lib/python3.6/dist-packages/chainer/utils/type_check.py", line 482, in expect
'{0} {1} {2}'.format(left, self.inv, right))
Will finalize trainer extensions and updater before reraising the exception.
---------------------------------------------------------------------------
InvalidType Traceback (most recent call last)
<ipython-input-25-9a17b0e6105a> in <module>()
1 model = MLP3Wrong() # MLP3Wrong
2 classifier_model = L.Classifier(model)
----> 3 train_and_test()
<ipython-input-7-78326c82d77b> in train_and_test()
19 ['epoch', 'iteration', 'main/loss', 'validation/main/loss',
20 'main/accuracy', 'validation/main/accuracy']), trigger=log_trigger)
---> 21 trainer.run()
22 elapsed_time = time.clock() - training_start
23 print('Elapsed time: %3.3f' % elapsed_time)
/usr/local/lib/python3.6/dist-packages/chainer/training/trainer.py in run(self, show_loop_exception_msg)
318 print('Will finalize trainer extensions and updater before '
319 'reraising the exception.', file=sys.stderr)
--> 320 six.reraise(*sys.exc_info())
321 finally:
322 for _, entry in extensions:
/usr/local/lib/python3.6/dist-packages/six.py in reraise(tp, value, tb)
691 if value.__traceback__ is not tb:
692 raise value.with_traceback(tb)
--> 693 raise value
694 finally:
695 value = None
/usr/local/lib/python3.6/dist-packages/chainer/training/trainer.py in run(self, show_loop_exception_msg)
304 self.observation = {}
305 with reporter.scope(self.observation):
--> 306 update()
307 for name, entry in extensions:
308 if entry.trigger(self):
/usr/local/lib/python3.6/dist-packages/chainer/training/updaters/standard_updater.py in update(self)
147
148 """
--> 149 self.update_core()
150 self.iteration += 1
151
/usr/local/lib/python3.6/dist-packages/chainer/training/updaters/standard_updater.py in update_core(self)
158
159 if isinstance(in_arrays, tuple):
--> 160 optimizer.update(loss_func, *in_arrays)
161 elif isinstance(in_arrays, dict):
162 optimizer.update(loss_func, **in_arrays)
/usr/local/lib/python3.6/dist-packages/chainer/optimizer.py in update(self, lossfun, *args, **kwds)
648 if lossfun is not None:
649 use_cleargrads = getattr(self, '_use_cleargrads', True)
--> 650 loss = lossfun(*args, **kwds)
651 if use_cleargrads:
652 self.target.cleargrads()
/usr/local/lib/python3.6/dist-packages/chainer/links/model/classifier.py in __call__(self, *args, **kwargs)
132 self.loss = None
133 self.accuracy = None
--> 134 self.y = self.predictor(*args, **kwargs)
135 self.loss = self.lossfun(self.y, t)
136 reporter.report({'loss': self.loss}, self)
<ipython-input-24-532380536ccf> in __call__(self, x)
9
10 def __call__(self, x):
---> 11 h1 = F.tanh(self.l1(x))
12 h2 = F.tanh(self.l2(x))
13 y = self.l3(h3)
/usr/local/lib/python3.6/dist-packages/chainer/links/connection/linear.py in __call__(self, x)
132 in_size = functools.reduce(operator.mul, x.shape[1:], 1)
133 self._initialize_params(in_size)
--> 134 return linear.linear(x, self.W, self.b)
/usr/local/lib/python3.6/dist-packages/chainer/functions/connection/linear.py in linear(x, W, b)
232 args = x, W, b
233
--> 234 y, = LinearFunction().apply(args)
235 return y
/usr/local/lib/python3.6/dist-packages/chainer/function_node.py in apply(self, inputs)
241
242 if configuration.config.type_check:
--> 243 self._check_data_type_forward(in_data)
244
245 hooks = chainer.get_function_hooks()
/usr/local/lib/python3.6/dist-packages/chainer/function_node.py in _check_data_type_forward(self, in_data)
326 in_type = type_check.get_types(in_data, 'in_types', False)
327 with type_check.get_function_check_context(self):
--> 328 self.check_type_forward(in_type)
329
330 def check_type_forward(self, in_types):
/usr/local/lib/python3.6/dist-packages/chainer/functions/connection/linear.py in check_type_forward(self, in_types)
21 x_type.ndim == 2,
22 w_type.ndim == 2,
---> 23 x_type.shape[1] == w_type.shape[1],
24 )
25 if type_check.eval(n_in) == 3:
/usr/local/lib/python3.6/dist-packages/chainer/utils/type_check.py in expect(*bool_exprs)
522 for expr in bool_exprs:
523 assert isinstance(expr, Testable)
--> 524 expr.expect()
525
526
/usr/local/lib/python3.6/dist-packages/chainer/utils/type_check.py in expect(self)
480 raise InvalidType(
481 '{0} {1} {2}'.format(self.lhs, self.exp, self.rhs),
--> 482 '{0} {1} {2}'.format(left, self.inv, right))
483
484
InvalidType:
Invalid operation is performed in: LinearFunction (Forward)
Expect: in_types[0].shape[1] == in_types[1].shape[1]
Actual: 784 != 748
Experiment 1.5 - Make your own model¶
Now it is your turn. Let’s modify the model by yourself to achieve higher accuracy.
Since increasing the number of epochs is obviously the easiest way, try to reach 0.95+ within 10 epochs & less than 100 sec. training.
Definition: define a new model with more options¶
Tune the neural network model for better performance. There are many options:
- Increase the number of epochs
- Increase the number of nodes
- Add more layers
- Use different types of activation functions
[ ]:
## Let's create new Multi-Layer Perceptron (MLP)
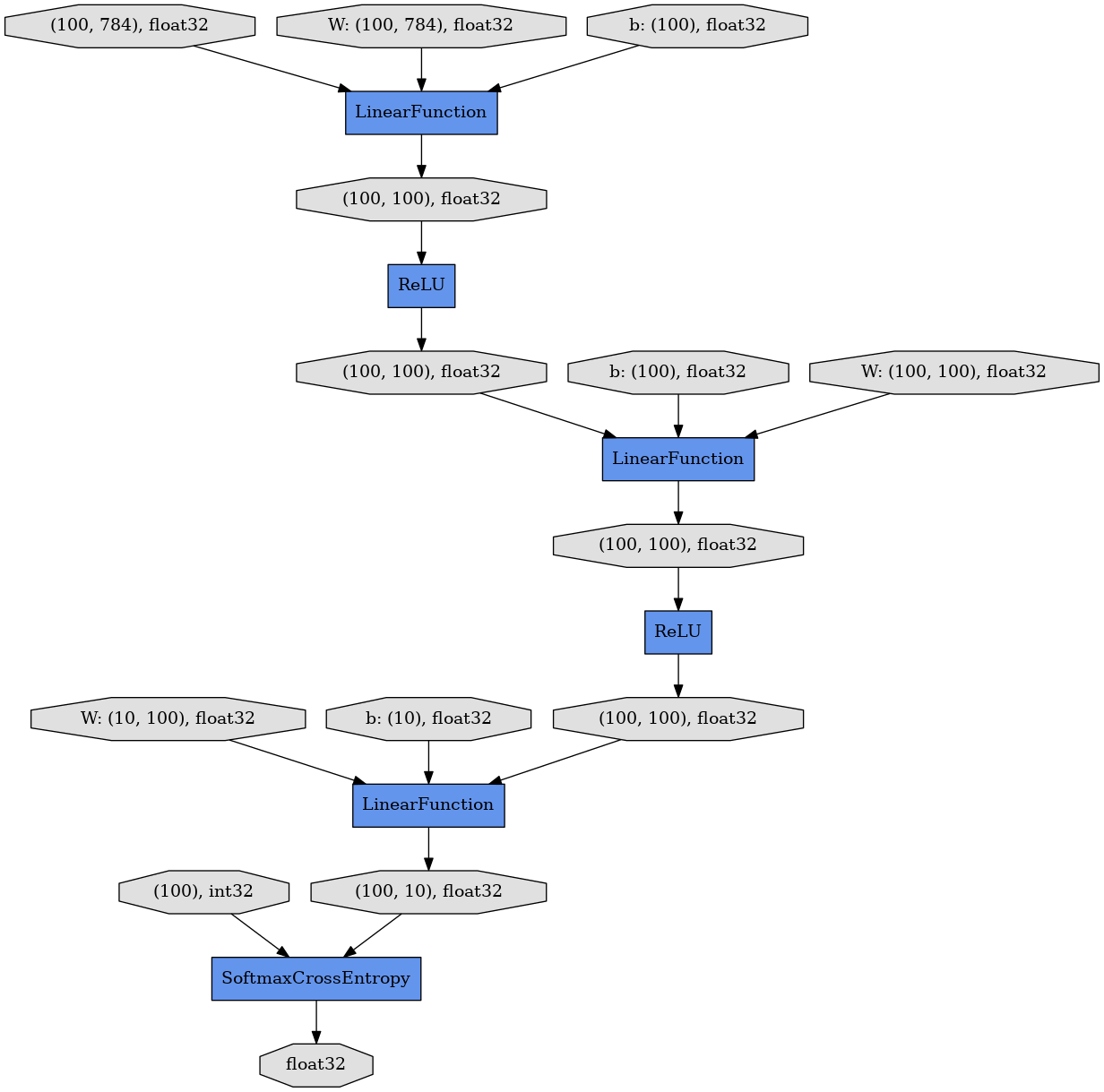
class MLPNew(Chain):
def __init__(self):
# Add more layers?
super(MLPNew, self).__init__(
l1=L.Linear(784, 100), # Increase output node as (784, 200)?
l2=L.Linear(100, 100), # Increase nodes as (200, 200)?
l3=L.Linear(100, 10) # Increase nodes as (200, 10)?
)
def __call__(self, x):
h1 = F.relu(self.l1(x)) # Replace F.tanh with F.sigmoid or F.relu ?
h2 = F.relu(self.l2(h1)) # Replace F.tanh with F.sigmoid or F.relu ?
y = self.l3(h2)
return y
enable_cupy = True # Use CuPy for faster training
n_epoch = 5 # Add more epochs?
Execution: create a better model with 0.95+ accuracy¶
[27]:
model = MLPNew()
classifier_model = L.Classifier(model)
train_and_test()
epoch iteration main/loss validation/main/loss main/accuracy validation/main/accuracy
1 600 1.37153 0.610667 0.64245 0.8477
2 1200 0.493793 0.387275 0.8697 0.894
3 1800 0.376693 0.329261 0.894701 0.9075
4 2400 0.332247 0.298809 0.904967 0.9143
5 3000 0.30512 0.280604 0.912418 0.92
Elapsed time: 20.306
Execution: no mistake anymore?¶
With 0.95+ accuracy, you may not find any misclassification in these 60 examples.
[28]:
plot_examples()

Advanced: Convolutional NN implementation¶
In this Section, we only used MLP with linear (fully-connected) layers. However, recent progress of deep learning in image recognition comes from a different type of network called Convolutional Neural Network (CNN).
Though it is beyond the scope of this hands-on, Chainer also include an example code for ImageNet classification that contains many variants of CNN.
Definition: AlexNet (ImageNet 2012 winner) model¶
AlexNet is the standard CNN that was used for winning ImageNet 2012 classification contest.
Chainer supports all of the commonly-used layers and functions so that users can re-implement such state-of-the-art models and extend it for their own problems. For example, AlexNet includes:
- Convolutional layer (L.Convolution2D)
- Max pooling (F.max_pooling_2d)
- Local response normalization (F.local_response_normalization)
- Dropout (F.dropout)
For more details on the functions, please refer to Standard Function implementations in Chainer reference manual.
[ ]:
## Definition of AlexNet
class AlexNet(chainer.Chain):
def __init__(self):
super(AlexNet, self).__init__(
conv1=L.Convolution2D(3, 96, 11, stride=4),
conv2=L.Convolution2D(96, 256, 5, pad=2),
conv3=L.Convolution2D(256, 384, 3, pad=1),
conv4=L.Convolution2D(384, 384, 3, pad=1),
conv5=L.Convolution2D(384, 256, 3, pad=1),
fc6=L.Linear(9216, 4096),
fc7=L.Linear(4096, 4096),
fc8=L.Linear(4096, 1000),
)
self.train = True
def __call__(self, x, t):
self.clear()
h = F.max_pooling_2d(F.relu(
F.local_response_normalization(self.conv1(x))), 3, stride=2)
h = F.max_pooling_2d(F.relu(
F.local_response_normalization(self.conv2(h))), 3, stride=2)
h = F.relu(self.conv3(h))
h = F.relu(self.conv4(h))
h = F.max_pooling_2d(F.relu(self.conv5(h)), 3, stride=2)
h = F.dropout(F.relu(self.fc6(h)), train=self.train)
h = F.dropout(F.relu(self.fc7(h)), train=self.train)
y = self.fc8(h)
return y
Section 2. Inside Chainer¶
In Section 1, we showed how to build and train neural networks in Chainer through image recognition. Users can also apply Chainer to their own problems other than such pattern recognition tasks.
Though we only combined preset layers and functions to build neural networks in the experiments, users may need to create new kinds of networks, by writing code for lower level of implementations, from scratch.
Chainer is designed to encourage users to rapidly make such prototype of new models, test it, and improve through trial-and-error. In the following, we explain the core components inside the Chainer.
3.1 NumPy and CuPy¶
NumPy is the widely-used library in Python for numerical computations based on CPU. On the other hand, neural networks can benefit from GPU for faster computatins of multi-dimensional arrays. However, NumPy does not support GPU so that Python users have to write GPU-specific code as in the initial version of Chainer.
Therefore, CuPy has been created and added to Chainer as a NumPy-compatible library based on CUDA. It currently supports many of the APIs in NumPy so that users can write CPU/GPU-agnostic code in most cases.
Execution: test NumPy¶
By using NumPy, create a matrix of size 1000x1000, transpose it, multiply 2 to each element, and repeat them for 5000 times.
[31]:
## import numpy as np
a = np.arange(1000000).reshape(1000, -1)
t1 = time.clock()
for i in range(5000):
a = np.arange(1000000).reshape(1000, -1)
b = a.T * 2
t2 = time.clock()
print(t2 -t1)
15.250113999999996
Execution: test CuPy¶
Execute the same computation with CuPy. It should be about 4 times faster than NumPy.
[32]:
## import cupy as cp
a = cp.arange(1000000).reshape(1000, -1)
t1 = time.clock()
for i in range(5000):
a = cp.arange(1000000).reshape(1000, -1)
b = a.T * 2
t2 = time.clock()
print(t2 -t1)
1.4757419999999968
Chainer’s feature - (2) CPU/GPU-compatible array manipulation¶
Since CuPy provides the same interface as NumPy as possible, users can switch them without modifying computation logic as follows.
[33]:
def xp_test(xp):
a = xp.arange(1000000).reshape(1000, -1)
t1 = time.clock()
for i in range(5000):
a = xp.arange(1000000).reshape(1000, -1)
b = a.T * 2
t2 = time.clock()
print(t2 -t1)
enable_cupy = False
xp_test(np if not enable_cupy else cp)
enable_cupy = True
xp_test(np if not enable_cupy else cp)
15.178259999999995
1.5018499999999904
3.2 Variable and Function¶
Variable and Function are two basic classes in Chainer. As their names suggest, Variable represents the values of variables and Function represents a static function on Variable.
Execution: Variable is a class for multi-dimensional arrays¶
Variable can be initialized with NumPy/CuPy-arrays and it will be stored in .data.
[34]:
x = Variable(np.asarray([[0, 2],[1, -3]]).astype(np.float32))
print(type(x))
print(type(x.data))
print(x.data)
<class 'chainer.variable.Variable'>
<class 'numpy.ndarray'>
[[ 0. 2.]
[ 1. -3.]]
Execution: Variable can move between CPU and GPU¶
By calling to_gpu() and to_cpu(), the content in .data can be either of the array in NumPy or CuPy.
[35]:
x.to_gpu()
print(type(x.data))
x.to_cpu()
print(type(x.data))
<class 'cupy.core.core.ndarray'>
<class 'numpy.ndarray'>
Execution: Function is used for transforming Variables¶
The actual computation is defined in forward() method, and the output must be also an instance of Variable.
[36]:
from chainer import function
class MyFunc(function.Function):
def forward(self, x):
self.y = x[0] **2 + 2 * x[0] + 1 # y = x^2 + 2x + 1
return self.y,
def my_func(x):
return MyFunc()(x)
x = Variable(np.asarray([[0, 2],[1, -3]]).astype(np.float32))
y = my_func(x)
print(type(x))
print(x.data)
print(type(y))
print(y.data)
<class 'chainer.variable.Variable'>
[[ 0. 2.]
[ 1. -3.]]
<class 'chainer.variable.Variable'>
[[1. 9.]
[4. 4.]]
Execution: Variable remembers history¶
Each instance of Variable remembers the function, which generates it, in .creator. If its .ceator is None, the Variable instance is called root.
[37]:
x = Variable(np.asarray([[0, 2],[1, -3]]).astype(np.float32))
## y is created by MyFunc
y = my_func(x)
print(y.creator)
## z is created by F.sigmoid
z = F.sigmoid(x)
print(z.creator)
## x is created by user
print(x.creator)
<__main__.MyFunc object at 0x7f409a6b3470>
<chainer.functions.activation.sigmoid.Sigmoid object at 0x7f409a6b3cc0>
None
Variable natively supports backpropagation¶
Backpropagation is the standard way to optimize neural networks. After forward computation, the loss is given at the output (as gradient), then the corresponding gradients are assigned to each intermediate layer by backtracking the computational graph. Then the parameters will be updated using the gradient information.
In Chainer, since all of the variables in forward computation are stored and automatic differentiation is supported, backward() traces the computational graph backward from the terminal (output) to the root (input of which .creator is None). Then the optimizer updates the model.
Definition: quadratic equation as forward computation¶
As shown in the previous section, forward computation can be regarded as a chain of functions to generate the final Variable instance. During the computation, Chainer remembers all of the intermediate Variable instances.
[ ]:
## A mock of forward computation
def forward(x):
z = 2 * x
y = x ** 2 - z + 1
return y, z
Execution: backward computation to assign gradients¶
By setting y.grad and call y.backward(), the gradient information will be transferred to x and z.
[ ]:
x = Variable(np.array([[1, 2, 3], [4, 5, 6]], dtype=np.float32))
y, z = forward(x)
y.grad = np.ones((2, 3), dtype=np.float32)
y.backward(retain_grad=True)
[40]:
## Gradient for x: 2*x - 2
print(x.grad)
[[ 0. 2. 4.]
[ 6. 8. 10.]]
[41]:
## Gradient for z: -1
print(z.grad)
[[-1. -1. -1.]
[-1. -1. -1.]]
3.3 Link and Chain¶
Function can represent a specific computation but it does not have any internal state. So it cannot be directly used for stateful elements in neural networks such as layers, of which states are used to represent the parameters.
Link is used as a wrapper to such Functions, with parameters. It is convenient to use Link as a reusable part to build a large network (an instance of Chain). Many of the common layers are provided under chianer.links. They can be used as L.XYZ, just like L.Linear.
Execution: Link is a stateful function with parameters¶
Most of the constructors of Link classes receive a few numbers to define the size of internal parameters. The parameters are also instances of Variable.
For example, L.Linear contains two parmeters, weight matrix W and bias term b. The constractor of L.Linear requires two values to specify the size of weight matrix and bias term.
[42]:
f = L.Linear(3, 2)
## Weight matrix for linear transformation (randomly initialized)
print(f.W.data)
## Bias term for linear transformation (initialized with zero)
print(f.b.data)
[[-0.25193685 0.26663136 -0.30745485]
[-0.74656004 -0.61045563 0.80746955]]
[0. 0.]
Execution: use instance of Link¶
The instance of Link can be called just like a function.
[43]:
## Apply linear transformation f()
x = Variable(np.array([[1, 2, 3], [4, 5, 6]], dtype=np.float32))
y = f(x)
print(y.data)
[[-0.64103866 0.45493728]
[-1.5193198 -1.1937011 ]]
Execution: compute gradient for Link¶
Since the parameters in Link are instances of Variable, the backward computation assigns gradients to them.
[44]:
## Initialize gradients of f
f.zerograds()
## Set gradient of y (= loss)
y.grad = np.ones((2, 2), dtype=np.float32)
## Backward computation
y.backward()
## Gradient for f.W and f.b
print(f.W.grad)
print(f.b.grad)
[[5. 7. 9.]
[5. 7. 9.]]
[2. 2.]
Definition: Chain is a set of Links = a network¶
The following class is exactly the same with MLP2 in Section 1, but it actually inherits Chain. As a base class of neural network model, Chain supports parameter management, to_cpu() and to_gpu() for migration between CPU and GPU, save/load, etc.
[ ]:
## 2-layer Multi-Layer Perceptron (MLP)
class MLP2(Chain):
# Initialization of layers (Link)
def __init__(self):
super(MLP2, self).__init__(
l1=L.Linear(784, 100),
l2=L.Linear(100, 10),
)
# Forward computation by __call__
def __call__(self, x):
h1 = F.tanh(self.l1(x))
y = self.l2(h1)
return y
Advanced: Define-by-Run scheme¶
In most of the existing deep learning frameworks, the model construction and training are two separate processes. In advance of training, a fixed computational graph for a model is built by parsing the model definition. Most of them use a text or symbolic style program to define a neural network. These definitions can be regarded as a kind of domain-specific language (DSL) for deep learning. Then, given a training dataset, actual training runs for updating the model. The following figure shows the two processes. We call it Define-and-Run scheme.
The Define-and-Run is very straightforward, and good for optimizing the computational graph before training. On the other hand, it has some drawbacks. For example, it requires special syntax to implement recurrent neural networks. The memory efficiency might not be optimal since all of the computational graph should be stored on the main memory from the beginning to the end of training.
Therefore, Chainer uses another approach named Define-by-Run. The model definition is combined with training as actual forward computation builds the computational graph on the fly. It enables users to easily implement complex networks with loops and branching by using host language. Modifications to the computational graph during the training such as truncated BPTT can also be done efficiently.
We would like interested users to refer to our research paper.
Section 3. Summary¶
We introduced Chainer as a poweruful, intuitive and flexible framework for deep learning. Chainer enables users to easily implement complex models proposed by recent academic papers and also rapidly make a prototype of new algorithms by themselves.
The following images were generate by a Chainer implementation of a famous paper “A neural algorithm of Artistic style”. The style of a content image of a cat is modified into artistic images of which style resembles the style images next to it.
This is just an example, but you can see how this kind of fancy models are implemented in only a few hundreds of lines of codes in Chainer. There is also a list of code examples provided by users for many use-cases.
This is the end of this hands-on. For more details, please refer to the official tutorial.