DCGAN: Generate the images with Deep Convolutional GAN¶
Note: This notebook is created from chainer/examples/dcgan. If you want to run it as script, please refer to the above link.
In this notebook, we generate images with generative adversarial network (GAN).

First, we execute the following cell and install “Chainer” and its GPU back end “CuPy”. If the “runtime type” of Colaboratory is GPU, you can run Chainer with GPU as a backend.
[2]:
!curl https://colab.chainer.org/install | sh -
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following NEW packages will be installed:
libcusparse8.0 libnvrtc8.0 libnvtoolsext1
0 upgraded, 3 newly installed, 0 to remove and 0 not upgraded.
Need to get 28.9 MB of archives.
After this operation, 71.6 MB of additional disk space will be used.
Get:1 http://archive.ubuntu.com/ubuntu artful/multiverse amd64 libcusparse8.0 amd64 8.0.61-1 [22.6 MB]
Get:2 http://archive.ubuntu.com/ubuntu artful/multiverse amd64 libnvrtc8.0 amd64 8.0.61-1 [6,225 kB]
Get:3 http://archive.ubuntu.com/ubuntu artful/multiverse amd64 libnvtoolsext1 amd64 8.0.61-1 [32.2 kB]
Fetched 28.9 MB in 2s (14.4 MB/s)
Selecting previously unselected package libcusparse8.0:amd64.
(Reading database ... 18408 files and directories currently installed.)
Preparing to unpack .../libcusparse8.0_8.0.61-1_amd64.deb ...
Unpacking libcusparse8.0:amd64 (8.0.61-1) ...
Selecting previously unselected package libnvrtc8.0:amd64.
Preparing to unpack .../libnvrtc8.0_8.0.61-1_amd64.deb ...
Unpacking libnvrtc8.0:amd64 (8.0.61-1) ...
Selecting previously unselected package libnvtoolsext1:amd64.
Preparing to unpack .../libnvtoolsext1_8.0.61-1_amd64.deb ...
Unpacking libnvtoolsext1:amd64 (8.0.61-1) ...
Setting up libnvtoolsext1:amd64 (8.0.61-1) ...
Setting up libcusparse8.0:amd64 (8.0.61-1) ...
Setting up libnvrtc8.0:amd64 (8.0.61-1) ...
Processing triggers for libc-bin (2.26-0ubuntu2.1) ...
Let’s import the necessary modules, then check the version of Chainer, NumPy, CuPy, Cuda and other execution environments.
[ ]:
import os
import numpy as np
import chainer
from chainer import cuda
import chainer.functions as F
import chainer.links as L
from chainer import Variable
from chainer.training import extensions
chainer.print_runtime_info()
Chainer: 4.4.0
NumPy: 1.14.5
CuPy:
CuPy Version : 4.4.1
CUDA Root : None
CUDA Build Version : 8000
CUDA Driver Version : 9000
CUDA Runtime Version : 8000
cuDNN Build Version : 7102
cuDNN Version : 7102
NCCL Build Version : 2213
1. Setting parameters¶
Here we set the parameters for training.
n_epoch: Epoch number. How many times we pass through the whole training data.n_units: Number of units. How many hidden state vectors each Recursive Neural Network node has.batchsize: Batch size. How many train data we will input as a block when updating parameters.n_label: Number of labels. Number of classes to be identified. Since there are 5 labels this time,5.epoch_per_eval: How often to perform validation.is_test: IfTrue, we use a small dataset.gpu_id: GPU ID. The ID of the GPU to use. For Colaboratory it is good to use0.
[ ]:
# parameters
n_epoch = 100 # number of epochs
n_hidden = 100 # number of hidden units
batchsize = 50 # minibatch size
snapshot_interval = 10000 # number of iterations per snapshots
display_interval = 100 # number of iterations per display the status
gpu_id = 0
out_dir = 'result'
seed = 0 # random seed
2. Preparation of training data and iterator¶
In this notebook, we will use the training data which are preprocessed by chainer.datasets.get_cifar10.
From Wikipedia, it says
The CIFAR-10 dataset (Canadian Institute For Advanced Research) is a collection of images that are commonly used to train machine learning and computer vision algorithms. It is one of the most widely used datasets for machine learning research.The CIFAR-10 dataset contains 60,000 32x32 color images in 10 different classes. The 10 different classes represent airplanes, cars, birds, cats, deer, dogs, frogs, horses, ships, and trucks. There are 6,000 images of each class.
Let’s retrieve the CIFAR-10 dataset by using Chainer’s dataset utility function get_cifar10. CIFAR-10 is a set of small natural images. Each example is an RGB color image of size 32x32. In the original images, each component of pixels is represented by one-byte unsigned integer. This function scales the components to floating point values in the interval [0, scale].
[ ]:
# Load the CIFAR10 dataset if args.dataset is not specified
train, _ = chainer.datasets.get_cifar10(withlabel=False, scale=255.)
Downloading from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz...
[ ]:
train_iter = chainer.iterators.SerialIterator(train, batchsize)
3. Preparation of the model¶
Let’s define the network. We will create the model called DCGAN(Deep Convolutional GAN). As shown below, it is a model using CNN(Convolutional Neural Network) as its name suggests.
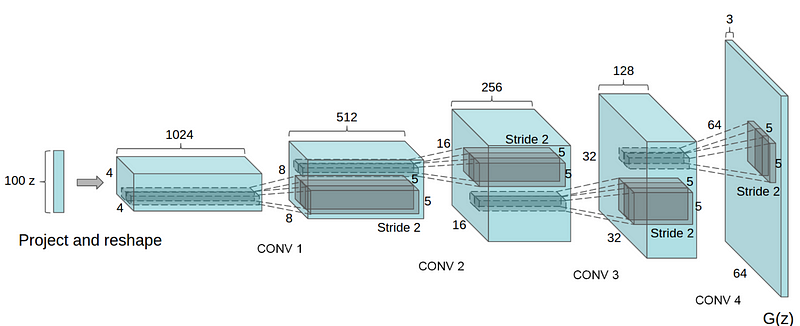 cited from [1]
cited from [1]
First, let’s define a network for the generator.
[ ]:
class Generator(chainer.Chain):
def __init__(self, n_hidden, bottom_width=4, ch=512, wscale=0.02):
super(Generator, self).__init__()
self.n_hidden = n_hidden
self.ch = ch
self.bottom_width = bottom_width
with self.init_scope():
w = chainer.initializers.Normal(wscale)
self.l0 = L.Linear(self.n_hidden, bottom_width * bottom_width * ch,
initialW=w)
self.dc1 = L.Deconvolution2D(ch, ch // 2, 4, 2, 1, initialW=w)
self.dc2 = L.Deconvolution2D(ch // 2, ch // 4, 4, 2, 1, initialW=w)
self.dc3 = L.Deconvolution2D(ch // 4, ch // 8, 4, 2, 1, initialW=w)
self.dc4 = L.Deconvolution2D(ch // 8, 3, 3, 1, 1, initialW=w)
self.bn0 = L.BatchNormalization(bottom_width * bottom_width * ch)
self.bn1 = L.BatchNormalization(ch // 2)
self.bn2 = L.BatchNormalization(ch // 4)
self.bn3 = L.BatchNormalization(ch // 8)
def make_hidden(self, batchsize):
return np.random.uniform(-1, 1, (batchsize, self.n_hidden, 1, 1)).astype(np.float32)
def __call__(self, z):
h = F.reshape(F.relu(self.bn0(self.l0(z))),
(len(z), self.ch, self.bottom_width, self.bottom_width))
h = F.relu(self.bn1(self.dc1(h)))
h = F.relu(self.bn2(self.dc2(h)))
h = F.relu(self.bn3(self.dc3(h)))
x = F.sigmoid(self.dc4(h))
return x
When we make a network in Chainer, we should follow some rules:
- Define a network class which inherits
Chain. - Make
chainer.links‘s instances in theinit_scope():of the initializer__init__. - Concatenate
chainer.links‘s instances withchainer.functionsto make the whole network.
If you are not familiar with constructing a new network, you can read this tutorial.
As we can see from the initializer __init__, the Generator uses the deconvolution layer Deconvolution2D and the batch normalization BatchNormalization. In __call__, each layer is concatenated by relu except the last layer.
Because the first argument of L.Deconvolution is the channel size of input and the second is the channel size of output, we can find that each layer halve the channel size. When we construct Generator with ch=1024, the network is same with the image above.
Note
Be careful when you concatenate a fully connected layer’s output and a convolutinal layer’s input. As we can see the 1st line of__call__, the output and input have to be concatenated with reshaping byreshape.
In addtion, let’s define a network for the discriminator.
[ ]:
class Discriminator(chainer.Chain):
def __init__(self, bottom_width=4, ch=512, wscale=0.02):
w = chainer.initializers.Normal(wscale)
super(Discriminator, self).__init__()
with self.init_scope():
self.c0_0 = L.Convolution2D(3, ch // 8, 3, 1, 1, initialW=w)
self.c0_1 = L.Convolution2D(ch // 8, ch // 4, 4, 2, 1, initialW=w)
self.c1_0 = L.Convolution2D(ch // 4, ch // 4, 3, 1, 1, initialW=w)
self.c1_1 = L.Convolution2D(ch // 4, ch // 2, 4, 2, 1, initialW=w)
self.c2_0 = L.Convolution2D(ch // 2, ch // 2, 3, 1, 1, initialW=w)
self.c2_1 = L.Convolution2D(ch // 2, ch // 1, 4, 2, 1, initialW=w)
self.c3_0 = L.Convolution2D(ch // 1, ch // 1, 3, 1, 1, initialW=w)
self.l4 = L.Linear(bottom_width * bottom_width * ch, 1, initialW=w)
self.bn0_1 = L.BatchNormalization(ch // 4, use_gamma=False)
self.bn1_0 = L.BatchNormalization(ch // 4, use_gamma=False)
self.bn1_1 = L.BatchNormalization(ch // 2, use_gamma=False)
self.bn2_0 = L.BatchNormalization(ch // 2, use_gamma=False)
self.bn2_1 = L.BatchNormalization(ch // 1, use_gamma=False)
self.bn3_0 = L.BatchNormalization(ch // 1, use_gamma=False)
def __call__(self, x):
h = add_noise(x)
h = F.leaky_relu(add_noise(self.c0_0(h)))
h = F.leaky_relu(add_noise(self.bn0_1(self.c0_1(h))))
h = F.leaky_relu(add_noise(self.bn1_0(self.c1_0(h))))
h = F.leaky_relu(add_noise(self.bn1_1(self.c1_1(h))))
h = F.leaky_relu(add_noise(self.bn2_0(self.c2_0(h))))
h = F.leaky_relu(add_noise(self.bn2_1(self.c2_1(h))))
h = F.leaky_relu(add_noise(self.bn3_0(self.c3_0(h))))
return self.l4(h)
The Discriminator network is almost same with the transposed network of the Generator. However, there are minor different points:
- Use
leaky_reluas activation functions - Deeper than
Generator - Add some noise when concatenating layers
[ ]:
def add_noise(h, sigma=0.2):
xp = cuda.get_array_module(h.data)
if chainer.config.train:
return h + sigma * xp.random.randn(*h.shape)
else:
return h
Let’s make the instances of the Generator and the Discriminator.
[ ]:
gen = Generator(n_hidden=n_hidden)
dis = Discriminator()
4. Preparing Optimizer¶
Next, let’s make optimizers for the models created above.
[ ]:
# Setup an optimizer
def make_optimizer(model, alpha=0.0002, beta1=0.5):
optimizer = chainer.optimizers.Adam(alpha=alpha, beta1=beta1)
optimizer.setup(model)
optimizer.add_hook(
chainer.optimizer_hooks.WeightDecay(0.0001), 'hook_dec')
return optimizer
[ ]:
opt_gen = make_optimizer(gen)
opt_dis = make_optimizer(dis)
5. Preparation and training of Updater · Trainer¶
The GAN need the two models: the generator and the discriminator. Usually, the default updaters pre-defined in Chainer take only one model. So, we need to define a custom updater for the GAN training.
The definition of DCGANUpdater is a little complicated. However, it just minimize the loss of the discriminator and that of the generator alternately. We will explain the way of updating the models.
As you can see in the class definiton, DCGANUpdater inherits StandardUpdater. In this case, almost all necessary functions are defined in StandardUpdater, we just override the functions of __init__ and update_core.
[ ]:
class DCGANUpdater(chainer.training.updaters.StandardUpdater):
def __init__(self, *args, **kwargs):
self.gen, self.dis = kwargs.pop('models')
super(DCGANUpdater, self).__init__(*args, **kwargs)
def loss_dis(self, dis, y_fake, y_real):
batchsize = len(y_fake)
L1 = F.sum(F.softplus(-y_real)) / batchsize
L2 = F.sum(F.softplus(y_fake)) / batchsize
loss = L1 + L2
chainer.report({'loss': loss}, dis)
return loss
def loss_gen(self, gen, y_fake):
batchsize = len(y_fake)
loss = F.sum(F.softplus(-y_fake)) / batchsize
chainer.report({'loss': loss}, gen)
return loss
def update_core(self):
gen_optimizer = self.get_optimizer('gen')
dis_optimizer = self.get_optimizer('dis')
batch = self.get_iterator('main').next()
x_real = Variable(self.converter(batch, self.device)) / 255.
xp = chainer.backends.cuda.get_array_module(x_real.data)
gen, dis = self.gen, self.dis
batchsize = len(batch)
y_real = dis(x_real)
z = Variable(xp.asarray(gen.make_hidden(batchsize)))
x_fake = gen(z)
y_fake = dis(x_fake)
dis_optimizer.update(self.loss_dis, dis, y_fake, y_real)
gen_optimizer.update(self.loss_gen, gen, y_fake)
In the intializer __init__, an addtional key word argument models is required as you can see the codes below. Also, we use key word arguments iterator, optimizer and device. Be careful for the optimizer. We needs not only two models but also two optimizers. So, we should input optimizer as dictionary {'gen': opt_gen, 'dis': opt_dis}. In the DCGANUpdater, you can access the iterator with self.get_iterator('main'). Also, you can access the optimizers with
self.get_optimizer('gen') and self.get_optimizer('dis').
In update_core, the two loss functions loss_dis and loss_gen are minimized by the optimizers. At first two lines, we access to the optimizers. Then, we generates next batch of training data by self.get_iterator('main').next(), and convert batch to x_real to make the training data suitable for self.device (e.g. GPU or CPU). After that, we minimize the loss functions with the optimizers.
[ ]:
updater = DCGANUpdater(
models=(gen, dis),
iterator=train_iter,
optimizer={
'gen': opt_gen, 'dis': opt_dis},
device=gpu_id)
trainer = chainer.training.Trainer(updater, (n_epoch, 'epoch'), out=out_dir)
[ ]:
from PIL import Image
import chainer.backends.cuda
def out_generated_image(gen, dis, rows, cols, seed, dst):
@chainer.training.make_extension()
def make_image(trainer):
np.random.seed(seed)
n_images = rows * cols
xp = gen.xp
z = Variable(xp.asarray(gen.make_hidden(n_images)))
with chainer.using_config('train', False):
x = gen(z)
x = chainer.backends.cuda.to_cpu(x.data)
np.random.seed()
x = np.asarray(np.clip(x * 255, 0.0, 255.0), dtype=np.uint8)
_, _, H, W = x.shape
x = x.reshape((rows, cols, 3, H, W))
x = x.transpose(0, 3, 1, 4, 2)
x = x.reshape((rows * H, cols * W, 3))
preview_dir = '{}/preview'.format(dst)
preview_path = preview_dir +\
'/image{:0>8}.png'.format(trainer.updater.iteration)
if not os.path.exists(preview_dir):
os.makedirs(preview_dir)
Image.fromarray(x).save(preview_path)
return make_image
[ ]:
snapshot_interval = (snapshot_interval, 'iteration')
display_interval = (display_interval, 'iteration')
trainer.extend(
extensions.snapshot(filename='snapshot_iter_{.updater.iteration}.npz'),
trigger=snapshot_interval)
trainer.extend(extensions.snapshot_object(
gen, 'gen_iter_{.updater.iteration}.npz'), trigger=snapshot_interval)
trainer.extend(extensions.snapshot_object(
dis, 'dis_iter_{.updater.iteration}.npz'), trigger=snapshot_interval)
trainer.extend(extensions.LogReport(trigger=display_interval))
trainer.extend(extensions.PrintReport([
'epoch', 'iteration', 'gen/loss', 'dis/loss',
]), trigger=display_interval)
trainer.extend(extensions.ProgressBar(update_interval=100))
trainer.extend(
out_generated_image(
gen, dis,
10, 10, seed, out_dir),
trigger=snapshot_interval)
[ ]:
# Run the training
trainer.run()
6. Checking the performance with test data¶
[ ]:
%%bash
ls result/preview
image00010000.png
image00020000.png
image00030000.png
image00040000.png
image00050000.png
image00060000.png
image00070000.png
image00080000.png
image00090000.png
image00100000.png
[ ]:
from IPython.display import Image, display_png
import glob
image_files = sorted(glob.glob(out_dir + '/preview/*.png'))
[ ]:
display_png(Image(image_files[0])) # first snapshot

[ ]:
display_png(Image(image_files[-1])) # last snapshot

Reference¶
[1] [Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks](https://arxiv.org/abs/1511.06434)