00 ColaboratoryでChainerを動かしてみよう¶
Chainer Begginer’s Hands-onの最初のNotebookをご覧いただきありがとうございます。
このNotebookの目的は以下の通りです。
- ColaboratoryでPython、Notebookの操作のおさらい
- ColaboratoryでChainerを使うための設定
- Chainerで衣類の画像を分類してみよう
ColaboratoryでChainerを使うための設定¶
必要なライブラリ・Chainer・CuPyのインストール¶
まずは、以下のコマンドでどのpythonパッケージがColaboratoryにプリインストールされているか確認しましょう。Chainer・CuPyがインストールされていないので、インストールする必要があります。
[1]:
!pip freeze
absl-py==0.6.1
altair==2.2.2
astor==0.7.1
atomicwrites==1.2.1
attrs==18.2.0
beautifulsoup4==4.6.3
bleach==3.0.2
cachetools==3.0.0
certifi==2018.10.15
chardet==3.0.4
crcmod==1.7
cycler==0.10.0
cymem==2.0.2
cytoolz==0.9.0.1
decorator==4.3.0
defusedxml==0.5.0
dill==0.2.8.2
entrypoints==0.2.3
future==0.16.0
gast==0.2.0
google-api-core==1.5.2
google-api-python-client==1.6.7
google-auth==1.4.2
google-auth-httplib2==0.0.3
google-auth-oauthlib==0.2.0
google-cloud-bigquery==1.1.0
google-cloud-core==0.28.1
google-cloud-language==1.0.2
google-cloud-storage==1.8.0
google-cloud-translate==1.3.1
google-colab==0.0.1a1
google-resumable-media==0.3.1
googleapis-common-protos==1.5.5
grpcio==1.15.0
h5py==2.8.0
httplib2==0.11.3
idna==2.6
ipykernel==4.6.1
ipython==5.5.0
ipython-genutils==0.2.0
Jinja2==2.10
joblib==0.13.0
jsonschema==2.6.0
jupyter-client==5.2.3
jupyter-core==4.4.0
Keras==2.2.4
Keras-Applications==1.0.6
Keras-Preprocessing==1.0.5
Markdown==3.0.1
MarkupSafe==1.1.0
matplotlib==2.1.2
mistune==0.8.4
more-itertools==4.3.0
mpmath==1.0.0
msgpack==0.5.6
msgpack-numpy==0.4.3.2
murmurhash==1.0.1
nbconvert==5.4.0
nbformat==4.4.0
networkx==2.2
nltk==3.2.5
notebook==5.2.2
numpy==1.14.6
oauth2client==4.1.3
oauthlib==2.1.0
olefile==0.46
opencv-python==3.4.3.18
pandas==0.22.0
pandas-gbq==0.4.1
pandocfilters==1.4.2
patsy==0.5.1
pexpect==4.6.0
pickleshare==0.7.5
Pillow==4.0.0
plac==0.9.6
plotly==1.12.12
pluggy==0.8.0
portpicker==1.2.0
preshed==2.0.1
prompt-toolkit==1.0.15
protobuf==3.6.1
psutil==5.4.8
ptyprocess==0.6.0
py==1.7.0
pyasn1==0.4.4
pyasn1-modules==0.2.2
Pygments==2.1.3
pygobject==3.26.1
pymc3==3.5
pyparsing==2.3.0
pystache==0.5.4
pytest==3.10.1
python-apt==1.6.3
python-dateutil==2.5.3
pytz==2018.7
PyWavelets==1.0.1
PyYAML==3.13
pyzmq==17.0.0
regex==2018.1.10
requests==2.18.4
requests-oauthlib==1.0.0
rsa==4.0
scikit-image==0.13.1
scikit-learn==0.19.2
scipy==1.1.0
seaborn==0.7.1
simplegeneric==0.8.1
six==1.11.0
spacy==2.0.16
statsmodels==0.8.0
sympy==1.1.1
tensorboard==1.12.0
tensorflow==1.12.0
tensorflow-hub==0.1.1
tensorflow-probability==0.5.0
termcolor==1.1.0
terminado==0.8.1
testpath==0.4.2
Theano==1.0.3
thinc==6.12.0
toolz==0.9.0
tornado==4.5.3
tqdm==4.28.1
traitlets==4.3.2
typing==3.6.6
ujson==1.35
uritemplate==3.0.0
urllib3==1.22
vega-datasets==0.5.0
wcwidth==0.1.7
webencodings==0.5.1
Werkzeug==0.14.1
wrapt==1.10.11
xgboost==0.7.post4
下記のスクリプト内では、GPUを動かすのに必要なパッケージのインストール、Chainerのインストール、cudaのバージョンに応じたCuPyのインストールが行われています。
本来なら適切なバージョンのCuPyをインストールする必要があります。しかし、上記スクリプトはColaboratoryにインストールされているcudaのバージョンを見て、自動的に適切なCuPyをインストールします。
[2]:
!curl https://colab.chainer.org/install | sh -
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1379 100 1379 0 0 4153 0 --:--:-- --:--:-- --:--:-- 4153
+ apt -y -q install cuda-libraries-dev-9-2
Reading package lists...
Building dependency tree...
Reading state information...
The following additional packages will be installed:
cuda-cublas-dev-9-2 cuda-cufft-dev-9-2 cuda-curand-dev-9-2
cuda-cusolver-dev-9-2 cuda-cusparse-dev-9-2 cuda-npp-dev-9-2
cuda-nvgraph-dev-9-2 cuda-nvrtc-dev-9-2
The following NEW packages will be installed:
cuda-cublas-dev-9-2 cuda-cufft-dev-9-2 cuda-curand-dev-9-2
cuda-cusolver-dev-9-2 cuda-cusparse-dev-9-2 cuda-libraries-dev-9-2
cuda-npp-dev-9-2 cuda-nvgraph-dev-9-2 cuda-nvrtc-dev-9-2
0 upgraded, 9 newly installed, 0 to remove and 5 not upgraded.
Need to get 332 MB of archives.
After this operation, 972 MB of additional disk space will be used.
Get:1 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1710/x86_64 cuda-cublas-dev-9-2 9.2.148.1-1 [50.4 MB]
Get:2 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1710/x86_64 cuda-cufft-dev-9-2 9.2.148-1 [106 MB]
Get:3 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1710/x86_64 cuda-curand-dev-9-2 9.2.148-1 [57.8 MB]
Get:4 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1710/x86_64 cuda-cusolver-dev-9-2 9.2.148-1 [8,184 kB]
Get:5 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1710/x86_64 cuda-cusparse-dev-9-2 9.2.148-1 [27.8 MB]
Get:6 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1710/x86_64 cuda-nvrtc-dev-9-2 9.2.148-1 [9,348 B]
Get:7 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1710/x86_64 cuda-nvgraph-dev-9-2 9.2.148-1 [30.1 MB]
Get:8 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1710/x86_64 cuda-npp-dev-9-2 9.2.148-1 [52.0 MB]
Get:9 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1710/x86_64 cuda-libraries-dev-9-2 9.2.148-1 [2,598 B]
Fetched 332 MB in 7s (50.5 MB/s)
Selecting previously unselected package cuda-cublas-dev-9-2.
(Reading database ... 22298 files and directories currently installed.)
Preparing to unpack .../0-cuda-cublas-dev-9-2_9.2.148.1-1_amd64.deb ...
Unpacking cuda-cublas-dev-9-2 (9.2.148.1-1) ...
Selecting previously unselected package cuda-cufft-dev-9-2.
Preparing to unpack .../1-cuda-cufft-dev-9-2_9.2.148-1_amd64.deb ...
Unpacking cuda-cufft-dev-9-2 (9.2.148-1) ...
Selecting previously unselected package cuda-curand-dev-9-2.
Preparing to unpack .../2-cuda-curand-dev-9-2_9.2.148-1_amd64.deb ...
Unpacking cuda-curand-dev-9-2 (9.2.148-1) ...
Selecting previously unselected package cuda-cusolver-dev-9-2.
Preparing to unpack .../3-cuda-cusolver-dev-9-2_9.2.148-1_amd64.deb ...
Unpacking cuda-cusolver-dev-9-2 (9.2.148-1) ...
Selecting previously unselected package cuda-cusparse-dev-9-2.
Preparing to unpack .../4-cuda-cusparse-dev-9-2_9.2.148-1_amd64.deb ...
Unpacking cuda-cusparse-dev-9-2 (9.2.148-1) ...
Selecting previously unselected package cuda-nvrtc-dev-9-2.
Preparing to unpack .../5-cuda-nvrtc-dev-9-2_9.2.148-1_amd64.deb ...
Unpacking cuda-nvrtc-dev-9-2 (9.2.148-1) ...
Selecting previously unselected package cuda-nvgraph-dev-9-2.
Preparing to unpack .../6-cuda-nvgraph-dev-9-2_9.2.148-1_amd64.deb ...
Unpacking cuda-nvgraph-dev-9-2 (9.2.148-1) ...
Selecting previously unselected package cuda-npp-dev-9-2.
Preparing to unpack .../7-cuda-npp-dev-9-2_9.2.148-1_amd64.deb ...
Unpacking cuda-npp-dev-9-2 (9.2.148-1) ...
Selecting previously unselected package cuda-libraries-dev-9-2.
Preparing to unpack .../8-cuda-libraries-dev-9-2_9.2.148-1_amd64.deb ...
Unpacking cuda-libraries-dev-9-2 (9.2.148-1) ...
Setting up cuda-npp-dev-9-2 (9.2.148-1) ...
Setting up cuda-curand-dev-9-2 (9.2.148-1) ...
Setting up cuda-nvrtc-dev-9-2 (9.2.148-1) ...
Setting up cuda-cusolver-dev-9-2 (9.2.148-1) ...
Setting up cuda-cufft-dev-9-2 (9.2.148-1) ...
Setting up cuda-cusparse-dev-9-2 (9.2.148-1) ...
Setting up cuda-cublas-dev-9-2 (9.2.148.1-1) ...
Setting up cuda-nvgraph-dev-9-2 (9.2.148-1) ...
Setting up cuda-libraries-dev-9-2 (9.2.148-1) ...
+ pip install -q cupy-cuda92 chainer
+ set +ex
Installation succeeded!
Chainer v4.0.0からchainer.print_runtime_info()という便利なメソッドが追加されました。以下のコマンドをターミナルで実行し、ChainerやCuPyが正しくインストールされたかを確認してみましょう。
[3]:
!python -c 'import chainer; chainer.print_runtime_info()'
Platform: Linux-4.14.65+-x86_64-with-Ubuntu-18.04-bionic
Chainer: 5.0.0
NumPy: 1.14.6
CuPy:
CuPy Version : 5.0.0
CUDA Root : /usr/local/cuda
CUDA Build Version : 9020
CUDA Driver Version : 9020
CUDA Runtime Version : 9020
cuDNN Build Version : 7201
cuDNN Version : 7201
NCCL Build Version : 2213
iDeep: Not Available
うまくインストールできていますね。
また、計算グラフの可視化にGraphvizを使いますので、こちらもインストールしておいてください。
[4]:
!apt -y -qq install graphviz > /dev/null 2> /dev/null
!pip install pydot
Collecting pydot
Downloading https://files.pythonhosted.org/packages/50/da/68cee64ad379462abb743ffb665fa34b214df85d263565ad2bd512c2d935/pydot-1.3.0-py2.py3-none-any.whl
Requirement already satisfied: pyparsing>=2.1.4 in /usr/local/lib/python3.6/dist-packages (from pydot) (2.3.0)
Installing collected packages: pydot
Successfully installed pydot-1.3.0
[ ]:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import chainer
Chainerで衣類の画像を分類してみよう¶
では、早速Chainerをつかってどんな機械学習の問題を解けるか試してみましょう!
今回解く問題は、スニーカー、Tシャツのような、白黒の衣類の画像を分類する問題です。
![]()
上記は、Fashion-MNISTというデータセットで、Zalandoというファッション記事のデータベースから作成されています。
Fashion-MNISTは、皆さんがご存知のMNISTと同じ性質を持つ、置き換え可能なデータセットです。Fashion-MNISTはMNISTに比べて分類する難易度が高い、互換性を有するデータセットいうことができるでしょう。
- 60,000枚の訓練用画像と、10,000枚のテスト用画像を含む。
- 各画像は縦横28x28のグレースケール画像(784次元ベクトル)。
- それぞれの画像には0から9までの正解ラベルIDが与えられている。
この問題で解くべきタスクは、与えられた画像のラベルIDを予測することであり、10クラス分類問題に相当します。
ラベルは、0から9までのIDで表現されており、それぞれ以下を意味します。
- 0 : T-shirt/top (Tシャツ)
- 1 : Trouser (ズボン)
- 2 : Pullover (パーカー)
- 3 : Dress (ドレス)
- 4 : Coat (コート)
- 5 : Sandal (サンダル)
- 6 : Shirt (シャツ)
- 7 : Sneaker (スニーカー)
- 8 : Bag (バッグ)
- 9 : Ankle boot (アンクルシューズ)
あとで使用するために、ラベルID labelからラベル名を取得する関数get_label_nameをここで定義しておきましょう。
[ ]:
LABEL_NAMES = [
'T-shirt/top',
'Trouser',
'Pullover',
'Dress',
'Coat',
'Sandal',
'Shirt',
'Sneaker',
'Bag',
'Ankle boot'
]
def get_label_name(label):
return LABEL_NAMES[label]
[7]:
for i in range(len(LABEL_NAMES)):
print(i, ' is ', get_label_name(i))
0 is T-shirt/top
1 is Trouser
2 is Pullover
3 is Dress
4 is Coat
5 is Sandal
6 is Shirt
7 is Sneaker
8 is Bag
9 is Ankle boot
データセットの中身を見てみよう¶
では、早速データセットをダウンロードし、その中身を見てみましょう。
教師あり学習の場合、データセットは「入力データ」と「それと対になるラベルデータ」 が必要になります。Chainerでは、上記2つをタプルで返すオブジェクトを必要とします。
ChainerにはMNISTやCIFAR10/100のようなよく用いられるデータセットに対して、データをダウンロードしてくるところからそのような機能をもったオブジェクトを作るところまで自動的にやってくれる便利なメソッドがあります。
Fashion-MNISTにも用意されているので、ここではひとまずこれを使いましょう。
[8]:
from chainer.datasets.fashion_mnist import get_fashion_mnist
# データセットがダウンロード済みでなければ、ダウンロードも行う
train, test = get_fashion_mnist(withlabel=True, ndim=1)
Downloading from http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz...
Downloading from http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz...
Downloading from http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz...
Downloading from http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz...
下記を実行して、データセットのサイズを確認しましょう。
上で説明したように、訓練用データは60,000、テスト用データは10,000でしょうか。
[9]:
print('Size of train', len(train))
print('Size of test', len(test))
Size of train 60000
Size of test 10000
では、テスト用データの1つ目の中身を見てみましょう。xは784次元のベクトルになっているはずです。
また、ラベルは9で、それは「Ankle boot」だとわかります。
[10]:
x, t = test[0]
print('Shape of x:', x.shape)
print('label:', t)
print('label name:', get_label_name(t))
Shape of x: (784,)
label: 9
label name: Ankle boot
本当に「Ankle boot」なのか確かめたいですよね。試しにplt.plotを使ってplotしてみましょう。
[11]:
plt.plot(x)
[11]:
[<matplotlib.lines.Line2D at 0x7f160496fe48>]
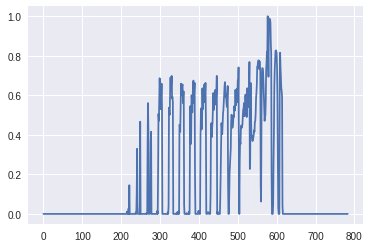
しかし、これだと0.0から1.0の値をとっていることはわかりますが、いったい何なのかわかりません。
画像として表示するためには、plt.imshowというものがあるのでこれを使ってみましょう。画像として表示するためには2次元配列に直す必要があるので、reshapeしています。
[12]:
plt.imshow(x.reshape(28, 28), cmap='gray')
[12]:
<matplotlib.image.AxesImage at 0x7f1602115278>
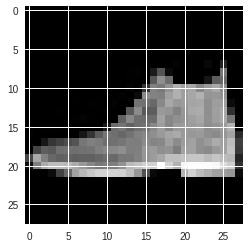
せっかくなので、それぞれのラベルの画像を表示してみましょう。
[13]:
for label_name in LABEL_NAMES:
this_data = ((x,t) for x, t in test if get_label_name(t) == label_name) # generator
x, t = next(this_data)
print(t, label_name)
plt.imshow(x.reshape(28, 28), cmap='gray')
plt.show()
0 T-shirt/top

1 Trouser
2 Pullover
3 Dress
4 Coat
5 Sandal
6 Shirt

7 Sneaker
8 Bag
9 Ankle boot
訓練データの分割¶
機械学習のモデルを評価するためには、訓練用データだけでなく、未知のデータに対する性能を評価するためのテスト用データが必要です。なぜなら、機械学習ではまだ見たことのない未知のデータに対してモデルが正しい結果を出力する必要があるからです。そのため、テスト用データを擬似的に未知のデータとして扱い、未知のデータに対する性能を評価します。
つまり、この段階で最低でも3つのデータに対する分類が存在します。
- 訓練用データ(train data):モデルの訓練に使用するデータ。
- テスト用データ(test data):モデルの未知のデータに対する性能を評価するデータ。
- 未知のデータ:モデルを運用したときに遭遇するデータ。モデルを作るときには存在しない。
ただし、モデルを訓練するとき、モデルの訓練とテストを1度だけ行って「お、テストでも性能が良かったからこれで終わり!」となることはありえません。なので、モデルのパラメータチューニングや比較を繰り返し行う必要があります。
その際に、テスト用データを使ってパラメータチューニングや比較を行うことはできません。なぜなら、パラメータチューニングや比較のためにテスト用データを使ってしまうと、その時点でテスト用データはモデルにとって未知のデータではなくなってしまうからです。
直感的な説明になってしまいますが、これらのデータを資格試験や入学試験にたとえてみようと思います。試験を受ける場合、基本的には以下のような段階を踏むと思います。
- テキストを読んで練習問題を解く
- ある程度練習問題が解けてきたら模擬試験の問題を解く
- 最後に本番の試験の問題を解く
なんとなくですが、1の問題は「訓練用データ」、3の問題はまだ見たことのない「未知のデータ」と例えられそうです。2の問題は、その人の合格確率(性能)を評価するという意味でテスト用データということができます。この時、パラメータチューニングや比較にテスト用データを使うというのはどういうことかというと、同じ模擬試験で何度も合格確率を評価するということを意味します。何度も同じ問題で合格率を評価すると、不当に合格率が高くなってしまうでしょう。それと同じ問題が機械学習でも発生します。
つまり、どういうことかというと、訓練用データ、テスト用データだけでなく、パラメータチューニングをするための検証用データが訓練時には必要になります。
- 訓練用データ(train data):モデルのトレーニングに使用するデータ。
- 検証用データ(validation data):最適なパラメータのモデルを選択するためのデータ。訓練用データを使って複数のパラメータでトレーニングした後、このデータを使ってモデルの性能を検証し、最も良いモデルを選択する。
- テスト用データ(test data):選択したモデルの未知のデータに対する性能を評価するデータ。
- 未知のデータ:モデルを運用したときに遭遇するデータ。モデルを作るときには存在しない。
上記の通り、検証用データも必要になるので、trainをtrainとvalidationに分割しましょう。Chainerにはデータセットを分割するためにsplit_dataset_randomという関数が用意されています。60,000個のtrainを50,000個のtrainと10,000個のvalidationに分割しましょう。
[ ]:
train, validation = chainer.datasets.split_dataset_random(train, 50000, seed=0)
課題¶
- 上記の文脈で、下記の言葉がどのような意味か調べて、説明を書いてみましょう。
- モデル選択
- 汎化誤差、汎化性能
- 過学習
- 交差検証
はじめてのモデルをトレーニングしよう¶
最も単純なニューラルネットワークモデルとして、2層の多層パーセプトロン(MLP2)を作ってみましょう。これは入力と出力、およびその間に1つの隠れユニットを持ちます。2つの線形レイヤー(全結合層)がそれらの間にあり、それぞれ重み行列とバイアス項をパラメータとして内蔵しています。隠れユニットに対する活性化関数はtanhを用います。
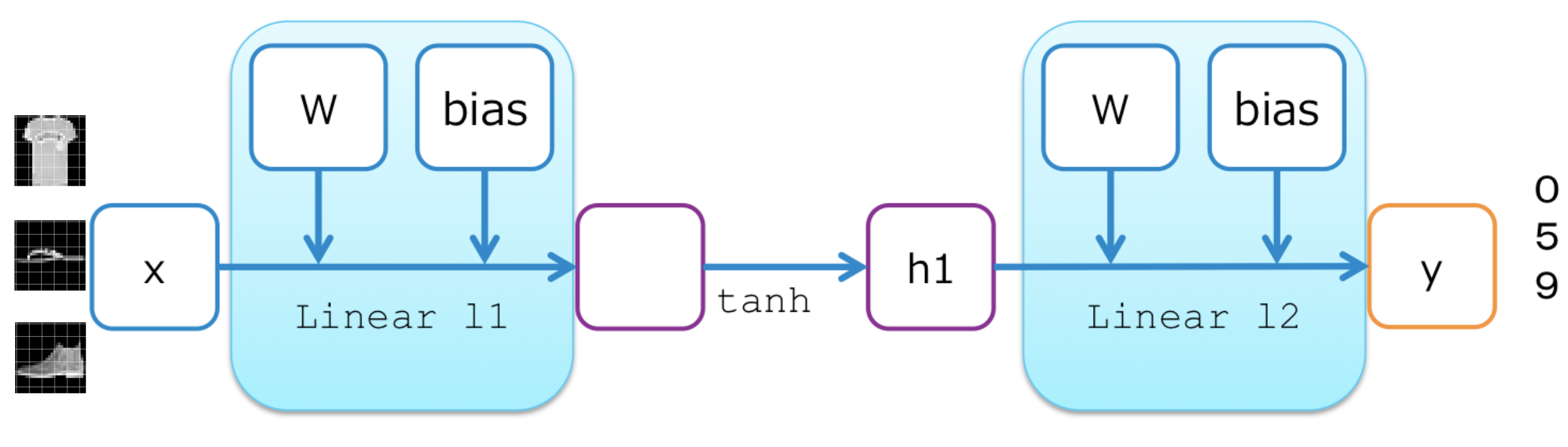
以下がMLP2を実装したクラスです。コンストラクタ(__init__)の中では各レイヤーの種類と大きさしか定義していないことに注意してください。実際の計算は別のforwardメソッド内に直接書かれています。
[ ]:
import chainer.functions as F
import chainer.links as L
from chainer import Chain
class MLP2(Chain):
# Initialization of layers
def __init__(self):
super(MLP2, self).__init__()
with self.init_scope():
self.l1=L.Linear(784, 200) # From 784-dimensional input to hidden unit with 200 nodes
self.l2=L.Linear(200, 10) # From hidden unit with 200 nodes to output unit with 10 nodes (10 classes)
# Forward computation
def forward(self, x):
h1 = F.tanh(self.l1(x)) # Forward from x to h1 through activation with tanh function
y = self.l2(h1) # Forward from h1to y
return y
ここで、作成したモデルを訓練し、検証を行う関数train_and_validateを定義します。以降でモデルをいくつか作りますが、全てこの関数で訓練と検証を行うことができます。簡単に中身を見てみましょう。以下のような工程を行っています。
- 与えられた
enable_cupyの値に応じて、CPUで訓練するか、GPUで訓練するか決める。 - 与えられた
optimizerにmodelを設定する - 与えられた訓練用データ
train、検証用データvalidationからそれぞれIteratorを作成する - Updater・Trainerを作成する
- Trainerの機能を拡張する
- ログ出力を行う
- 検証用データの計算を行う
- 標準出力に指定した指標を表示する
- 画像として損失関数の値を保存する
- 画像として精度を保存する
- 訓練を開始する
ここではChainerの様々な機能を使っています。なんでこんな事ができるのだろう?、他にどのようなことができるのだろう?と疑問に思うかもしれませんが、次回以降のハンズオンで説明を行います。ただ、どうしても今すぐ知りたい方はChainer v4 ビギナー向けチュートリアルを参照してみてください。
[ ]:
from chainer import optimizers, training
from chainer.training import extensions
def train_and_validate(
model, optimizer, train, validation, n_epoch, batchsize, device):
# 1. deviceがgpuであれば、gpuにモデルのデータを転送する
if device >= 0:
model.to_gpu(device)
# 2. Optimizerを設定する
optimizer.setup(model)
# 3. DatasetからIteratorを作成する
train_iter = chainer.iterators.SerialIterator(train, batchsize)
validation_iter = chainer.iterators.SerialIterator(
validation, batchsize, repeat=False, shuffle=False)
# 4. Updater・Trainerを作成する
updater = training.StandardUpdater(train_iter, optimizer, device=device)
trainer = chainer.training.Trainer(updater, (n_epoch, 'epoch'), out='out')
# 5. Trainerの機能を拡張する
trainer.extend(extensions.LogReport())
trainer.extend(extensions.Evaluator(validation_iter, model, device=device), name='val')
trainer.extend(extensions.PrintReport(
['epoch', 'main/loss', 'main/accuracy', 'val/main/loss', 'val/main/accuracy', 'elapsed_time']))
trainer.extend(extensions.PlotReport(
['main/loss', 'val/main/loss'],x_key='epoch', file_name='loss.png'))
trainer.extend(extensions.PlotReport(
['main/accuracy', 'val/main/accuracy'], x_key='epoch', file_name='accuracy.png'))
trainer.extend(extensions.dump_graph('main/loss'))
# 6. 訓練を開始する
trainer.run()
最初の実験として、CPUで訓練を行います。エポック数(n_epoch、各サンプルが訓練中に何度使われるか)は5に固定します。
また、ミニバッチサイズ(batchsize、一度のパラメータ更新に何サンプルを損失関数の計算に用いるか)は256を使用します。
L.Classifier はニューラルネットワーク(ここではMLP2)を内蔵した分類モデルです。デフォルトの損失関数はSoftmax cross entropyです。MLP2を分類モデルにするため使用します。
Optimizerはモデルのパラメータ(ここではMLP2中の線形レイヤー中の重み行列とバイアス項)を更新するために使われます。Chainerはよく使われる最適化アルゴリズムの多くをサポート しています(SGD, AdaGrad, RMSProp, Adam, etc…)。ここではSGDを使用します。
[ ]:
device = -1 # specify gpu id. if device == -1, use cpu
n_epoch = 5 # Only 5 epochs
batchsize = 256
model = MLP2() # MLP2 model
classifier_model = L.Classifier(model)
optimizer = optimizers.SGD()
train_and_validateを実行して、モデルの訓練と検証を行いましょう。
[18]:
train_and_validate(
classifier_model, optimizer, train, validation, n_epoch, batchsize, device)
epoch main/loss main/accuracy val/main/loss val/main/accuracy elapsed_time
1 1.43116 0.595285 1.04177 0.675781 2.89107
2 0.911606 0.712179 0.845551 0.720703 6.09436
3 0.781389 0.749479 0.755996 0.750781 9.39273
4 0.711757 0.770169 0.702938 0.76875 12.6888
5 0.664691 0.784756 0.664363 0.777734 15.9403
検証用データにおける精度(val/main/accuracy)は78%程度だと思います。まだまだ精度は良くないので、今後の実験で精度向上を目指しましょう。
Chainerは入力から損失関数までの計算グラフを出力できます。show_graphはそのために定義した関数です。
[ ]:
import pydot
from IPython.display import Image, display
def show_graph():
graph = pydot.graph_from_dot_file('out/cg.dot') # load from .dot file
graph[0].write_png('graph.png')
display(Image('graph.png', width=600, height=600))
[20]:
show_graph()
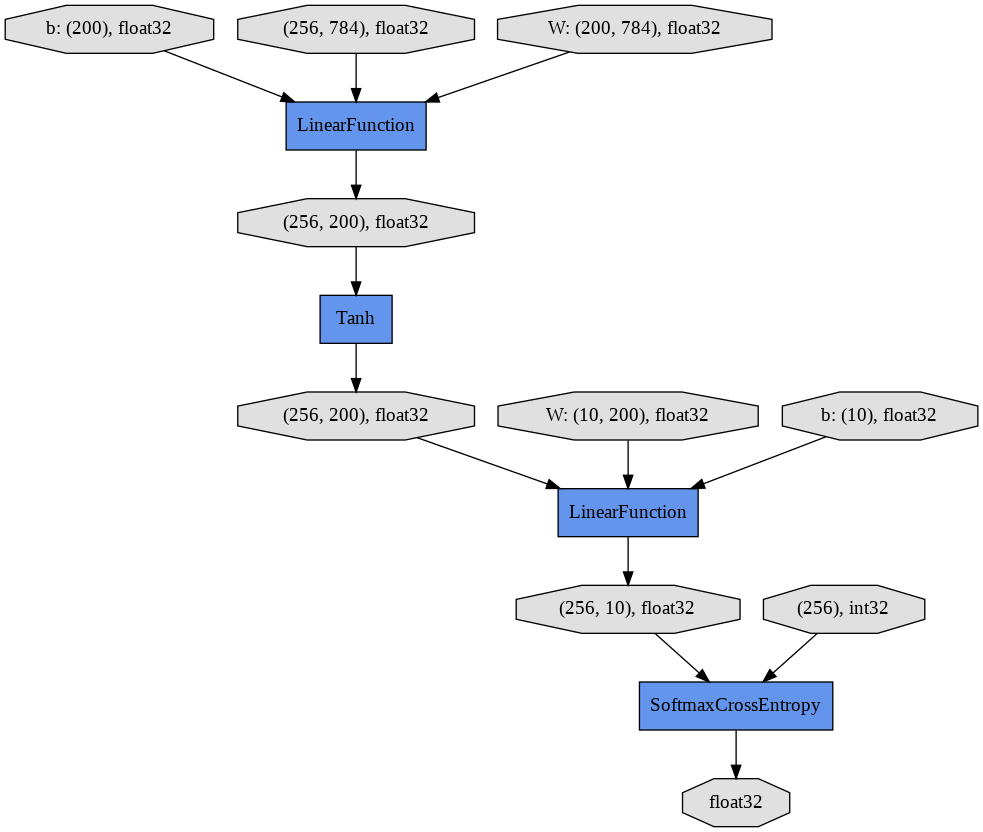
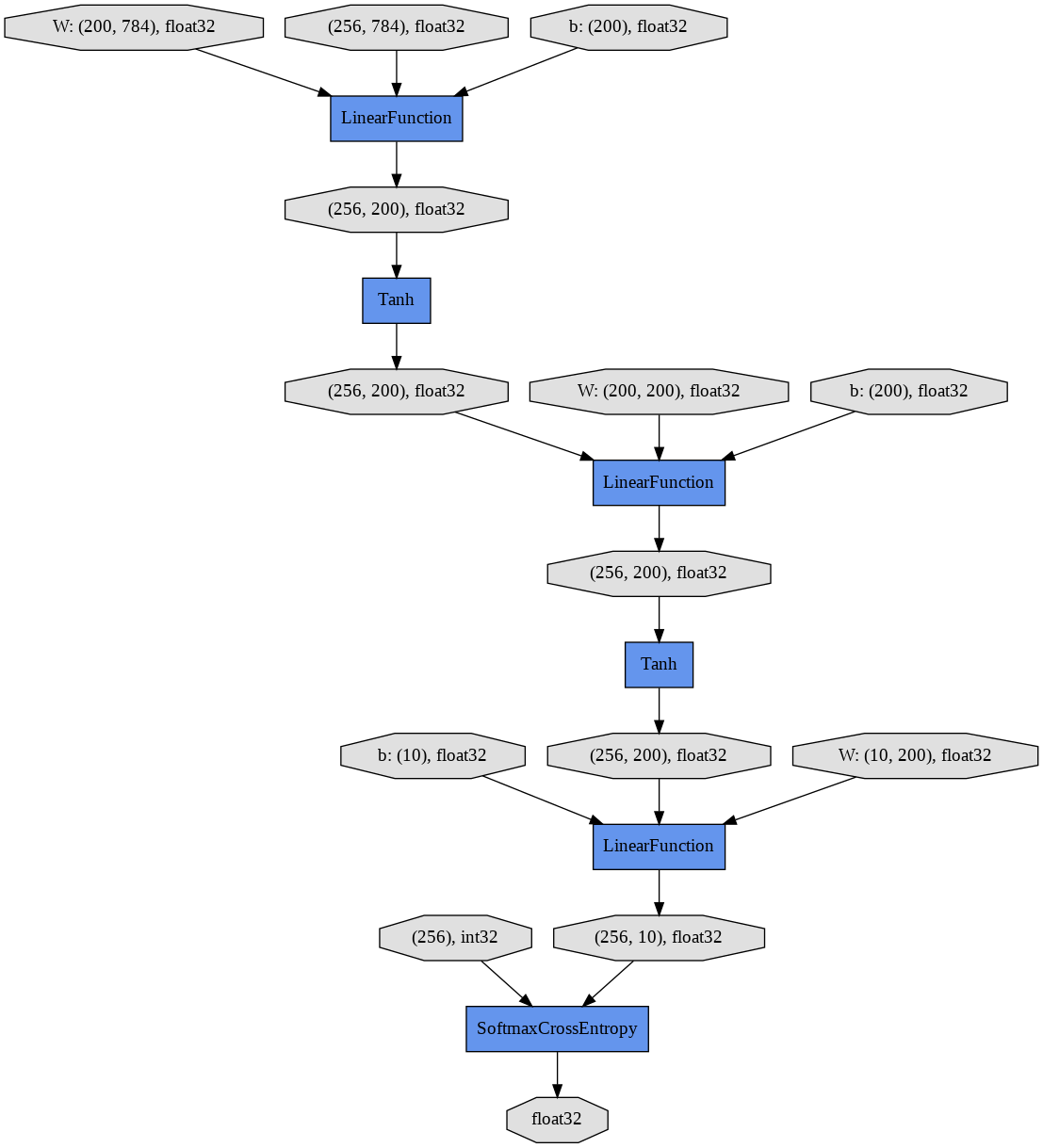
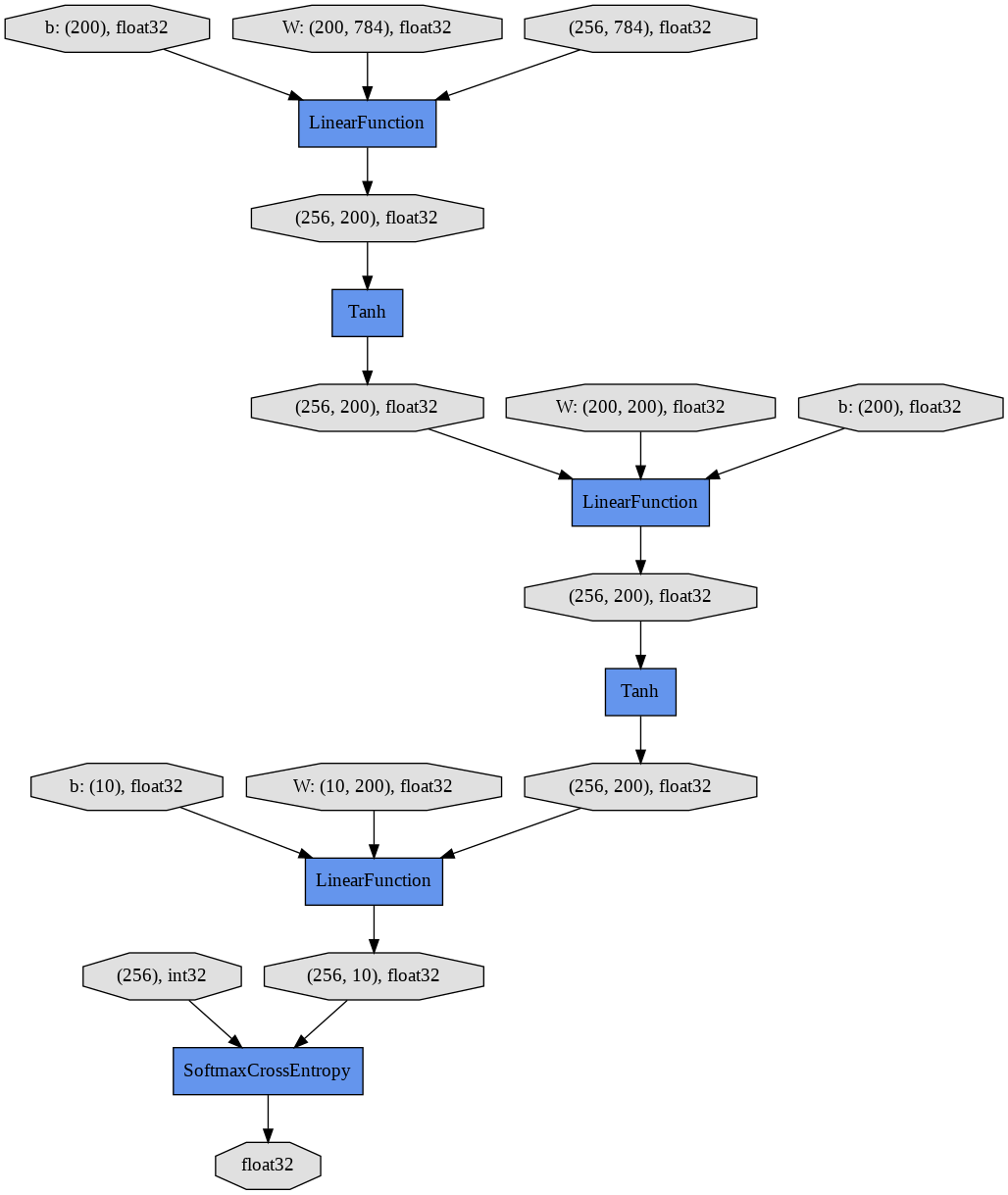
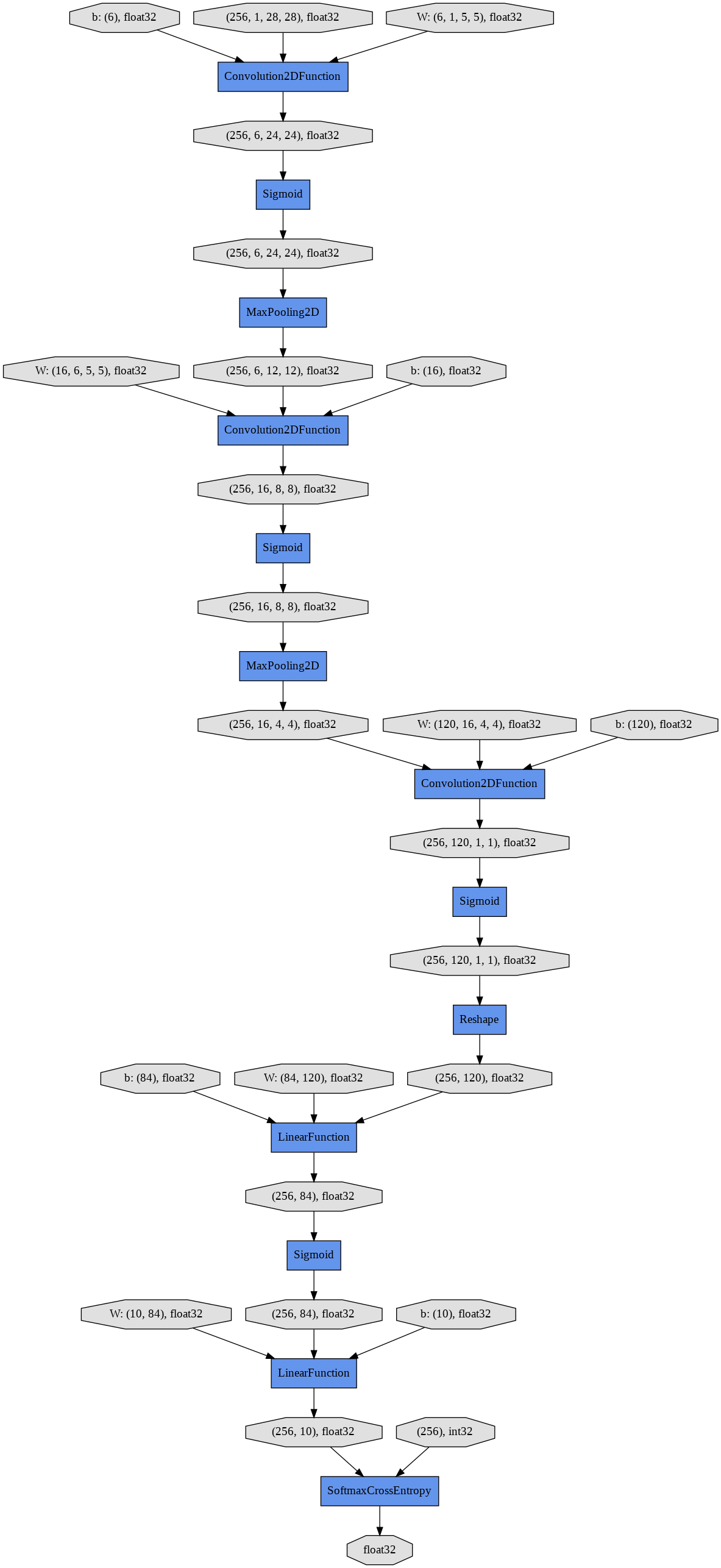
show_graphを実行することで、有向グラフが表示されます。一番上の3つの楕円形がそれぞれ784次元の画像256サンプル、線形レイヤーの対応する784x200の大きさの重み行列、長さ200のバイアス項ベクトル、を表します。
中間の隠れユニット(256x200)は活性化関数tanhを通して次の線形レイヤーの入力となります。ニューラルネットワークの出力である長さ10の256ベクトルは正解であるint32のリストと比較され、SoftmaxCrossEntropy関数によって損失がfloat32の値として算出されます。
extentionにより画像として保存した損失と、精度を表示してみましょう。
[ ]:
def show_loss_and_accuracy():
display(Image(filename='out/loss.png'))
display(Image(filename='out/accuracy.png'))
[22]:
show_loss_and_accuracy()
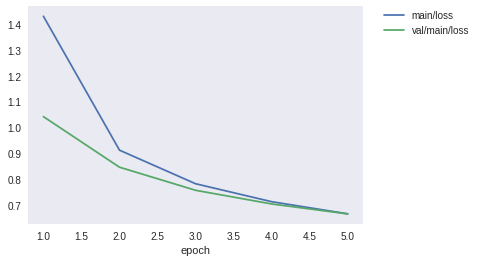
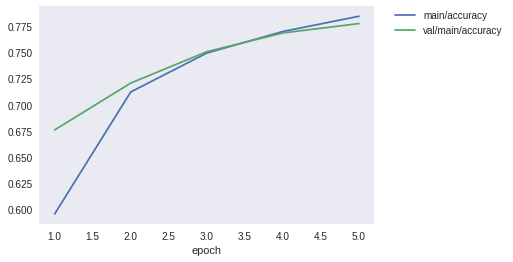
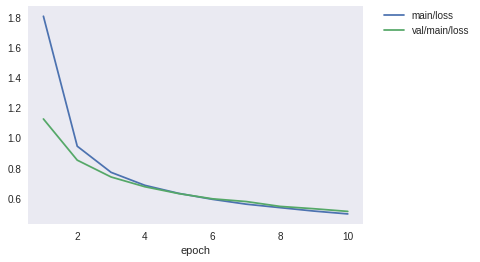
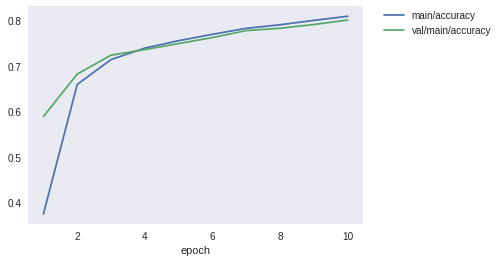
上記を見ると、エポックごとに損失は減少し、精度は向上していることがわかると思います。また、グラフとして可視化することによって、エポック数を増やすことによってまだまだ性能は改善しそうなことがわかると思います。ここに性能を可視化するメリットがあります。
テスト用データセットのFashion-MNIST画像60サンプルをプロットします。画像上部の「Answer」がデータセットで与えられた正解であり、「Predict」が現在の分類モデルによる予測結果です。
[ ]:
from chainer import Variable
def show_examples(model, test, device):
plt.figure(figsize=(12,50))
if device >= 0:
model.to_cpu()
for i in range(45, 105):
data, label = test[i] # test data, label
x = Variable(np.asarray([data]))
t = Variable(np.asarray([label])) # labels
y = model(x)
prediction = y.data.argmax(axis=1)
example = (data * 255).astype(np.int32).reshape(28, 28)
plt.subplot(20, 5, i - 44)
plt.imshow(example, cmap='gray')
plt.title("No.{0}\nAnswer:{1}\nPredict:{2}".format(
i,
get_label_name(label),
get_label_name(prediction[0])
))
plt.axis("off")
plt.tight_layout()
[24]:
show_examples(model, test, device)

多くのサンプルは正しく分類されていますが、誤りも見受けられます。例えば、1行目のNo. 45の画像が「Ankle boot」と予測されているとおもいますが、正解は「Sneaker」です。また、6行目のNo. 72の画像が「T-shirt/top」と予測されているとおもいますが、正解は「Pullover」です。
最後に、本当に未知のデータでも性能を発揮するか、テスト用データにおける精度も評価してみましょう。テスト用データでの精度を表示する関数print_test_performanceをここで定義します。
[ ]:
def show_test_performance(model, test, device, batchsize=256):
if device >=0:
model.to_gpu()
test_iter = chainer.iterators.SerialIterator(
test, batchsize, repeat=False, shuffle=False
)
test_evaluator = extensions.Evaluator(test_iter, model, device=device)
results = test_evaluator()
print('Test accuracy:', results['main/accuracy'])
[26]:
show_test_performance(classifier_model, test, device)
Test accuracy: 0.77568359375
78%程度ということで、検証用データにおける精度とほぼ同じ精度をテスト用データでも達成できていることがわかります。
「はじめてのモデルをトレーニングしよう」はいかがだったでしょうか。この1連の手順を行うことで、機械学習のモデルを作ることができます。この後は、この手順をGPUを用いて高速化したり、モデルの性能を向上させたりしていきましょう!
CuPyでGPUを計算に使って学習を高速化してみよう¶
上記の実験では、エポック数5で13秒程度かかっていることがわかります。
次の実験では、CuPyを有効にしてGPUを使うことでこの訓練を高速化してみましょう。
[27]:
device = 0
n_epoch = 5
batchsize = 256
model = MLP2()
classifier_model = L.Classifier(model)
optimizer = optimizers.SGD()
train_and_validate(
classifier_model, optimizer, train, validation, n_epoch, batchsize, device)
epoch main/loss main/accuracy val/main/loss val/main/accuracy elapsed_time
1 1.40635 0.593531 1.0421 0.675098 9.53265
2 0.916661 0.713942 0.844453 0.721484 12.3957
3 0.783174 0.750901 0.754338 0.748535 15.2264
4 0.711263 0.772521 0.698766 0.77002 18.1207
5 0.663209 0.787179 0.660558 0.780957 20.9783
同じモデルをGPUで訓練した場合の実行時間を比べると、この環境ではGPUによる訓練はCPUに比べて2/3程度になります。ただ、計算時間は以下の状況等によって変化します。
- GPU機種:基本的に新機種ほど、GPUのスペックが良いので、計算時間が速くなる。
- batchsize:値が大きいほど、一度にたくさんの計算を行うことができるので、総計算時間は速くなる。
- モデル:1命令あたりの計算量が多いモデルほど、GPUによって計算を並列化しやすいので、CPUに比べ計算効率が良くなる。
GPUは、行列演算などの単純な計算を大規模に並列計算するのに向いているプロセッサなので、それを活かすような計算だと高速化されることが多いです。
GPUを使うことで高速化されることが確認されたので、これ以降はGPUを使用していきましょう。
より「深い」モデルを学習させてみよう¶
今度はレイヤーを増やした異なる多層パーセプトロンを用いてみましょう。
以下のMLP3は3つの線形レイヤーでつながれた同じ200ノードからなる2つの隠れユニットを持ちます。順方向計算でtanhを活性化関数を用いるのも同様です。
[ ]:
## 3-layer multi-Layer Perceptron (MLP)
class MLP3(Chain):
def __init__(self):
super(MLP3, self).__init__()
with self.init_scope():
self.l1=L.Linear(784, 200)
self.l2=L.Linear(200, 200) # Additional layer
self.l3=L.Linear(200, 10)
def forward(self, x):
h1 = F.tanh(self.l1(x)) # Hidden unit 1
h2 = F.tanh(self.l2(h1)) # Hidden unit 2
y = self.l3(h2)
return y
[30]:
device = 0
n_epoch = 5
batchsize = 256
model = MLP3() # Use MLP3 instead of MLP2
classifier_model = L.Classifier(model)
optimizer = optimizers.SGD()
train_and_validate(
classifier_model, optimizer, train, validation, n_epoch, batchsize, device)
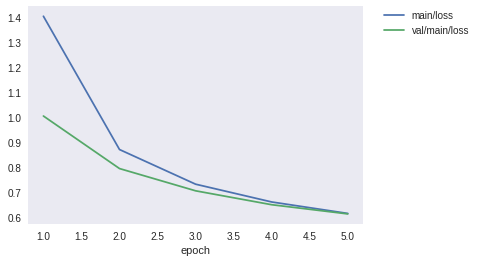
epoch main/loss main/accuracy val/main/loss val/main/accuracy elapsed_time
1 1.40331 0.609156 1.00402 0.695605 2.71036
2 0.869864 0.727925 0.7937 0.742969 5.94136
3 0.731161 0.76244 0.704657 0.759668 9.21122
4 0.660004 0.780752 0.648986 0.780273 12.5445
5 0.614135 0.79377 0.612189 0.79082 15.8007
MLP2とMLP3を比較すると以下のことが言えます。
- MLP3は高い表現力によって、検証用データにおいて、MLP2よりも低い損失と高い精度を達成している
- 一方、内部パラメータも増えるため、訓練に必要な時間はわずかに増加する
新しいモデルMLP3の計算グラフも表示してみましょう。新しい計算グラフは3つのLinearFunctionと2つのTanh活性化関数を含みます。
[31]:
show_graph()
同様に、損失と精度もグラフとして表示してみましょう。
[32]:
show_loss_and_accuracy()
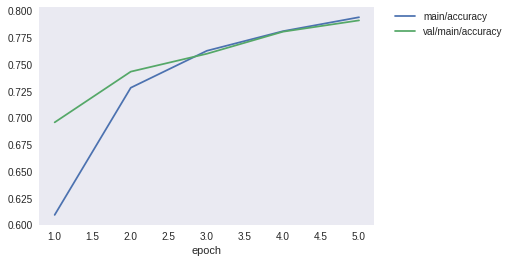
新しいモデルの分類結果はどうでしょうか。
[33]:
show_examples(model, test, device)

依然として、No. 45の画像を誤分類していますが、No. 72の画像は「Pullover」と正しく分類するようになりました。
Chainerのモデルをデバッグしてみよう¶
Chainerの特長の1つとして、デバッグのしやすさが挙がります。 複雑なニューラルネットワークのデバッグは面倒です、なぜなら一般のフレームワークはモデル定義や実装のどこが間違っているのか、直接的には教えてくれない事が多いからです。しかし、Chainerでは普通のプログラムをデバッグするかのように行うことができ、順方向計算中の型チェックもサポートしています。
以下のMLP3Wrongは、MLP3に3つのバグをわざと埋め込んだものです。実行しながら1つ1つ解決してみましょう。
[ ]:
## Find three bugs in this model definition
class MLP3Wrong(Chain):
def __init__(self):
super(MLP3Wrong, self).__init__()
with self.init_scope():
self.l1=L.Linear(748, 200)
self.l2=L.Linear(200, 200)
self.l3=L.Linear(200, 10)
def forward(self, x):
h1 = F.tanh(self.l1(x))
h2 = F.tanh(self.l2(x))
y = self.l3(h3)
return y
以下を実行するとエラーが発生しますが、スタックトレースの表示を下まで追うとそれが順方向計算においてどのソースコードのどの行で発生しているかがわかります。これはChainerのDefine-by-Runが、計算グラフを順方向計算中に直接構築しているため可能なことです。
[35]:
device = 0
n_epoch = 5
batchsize = 256
model = MLP3Wrong()
classifier_model = L.Classifier(model)
optimizer = optimizers.SGD()
train_and_validate(
classifier_model, optimizer, train, validation, n_epoch, batchsize, device)
Exception in main training loop:
Invalid operation is performed in: LinearFunction (Forward)
Expect: x.shape[1] == W.shape[1]
Actual: 784 != 748
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/chainer/training/trainer.py", line 315, in run
update()
File "/usr/local/lib/python3.6/dist-packages/chainer/training/updaters/standard_updater.py", line 165, in update
self.update_core()
File "/usr/local/lib/python3.6/dist-packages/chainer/training/updaters/standard_updater.py", line 177, in update_core
optimizer.update(loss_func, *in_arrays)
File "/usr/local/lib/python3.6/dist-packages/chainer/optimizer.py", line 680, in update
loss = lossfun(*args, **kwds)
File "/usr/local/lib/python3.6/dist-packages/chainer/link.py", line 242, in __call__
out = forward(*args, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/chainer/links/model/classifier.py", line 143, in forward
self.y = self.predictor(*args, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/chainer/link.py", line 242, in __call__
out = forward(*args, **kwargs)
File "<ipython-input-34-89fc8be176b0>", line 11, in forward
h1 = F.tanh(self.l1(x))
File "/usr/local/lib/python3.6/dist-packages/chainer/link.py", line 242, in __call__
out = forward(*args, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/chainer/links/connection/linear.py", line 138, in forward
return linear.linear(x, self.W, self.b, n_batch_axes=n_batch_axes)
File "/usr/local/lib/python3.6/dist-packages/chainer/functions/connection/linear.py", line 289, in linear
y, = LinearFunction().apply(args)
File "/usr/local/lib/python3.6/dist-packages/chainer/function_node.py", line 245, in apply
self._check_data_type_forward(in_data)
File "/usr/local/lib/python3.6/dist-packages/chainer/function_node.py", line 330, in _check_data_type_forward
self.check_type_forward(in_type)
File "/usr/local/lib/python3.6/dist-packages/chainer/functions/connection/linear.py", line 27, in check_type_forward
x_type.shape[1] == w_type.shape[1],
File "/usr/local/lib/python3.6/dist-packages/chainer/utils/type_check.py", line 546, in expect
expr.expect()
File "/usr/local/lib/python3.6/dist-packages/chainer/utils/type_check.py", line 483, in expect
'{0} {1} {2}'.format(left, self.inv, right))
Will finalize trainer extensions and updater before reraising the exception.
---------------------------------------------------------------------------
InvalidType Traceback (most recent call last)
<ipython-input-35-4b426e0e5f62> in <module>()
7 optimizer = optimizers.SGD()
8 train_and_validate(
----> 9 classifier_model, optimizer, train, validation, n_epoch, batchsize, device)
<ipython-input-16-3511217658e1> in train_and_validate(model, optimizer, train, validation, n_epoch, batchsize, device)
33
34 # 6. 訓練を開始する
---> 35 trainer.run()
/usr/local/lib/python3.6/dist-packages/chainer/training/trainer.py in run(self, show_loop_exception_msg)
327 f.write('Will finalize trainer extensions and updater before '
328 'reraising the exception.\n')
--> 329 six.reraise(*sys.exc_info())
330 finally:
331 for _, entry in extensions:
/usr/local/lib/python3.6/dist-packages/six.py in reraise(tp, value, tb)
691 if value.__traceback__ is not tb:
692 raise value.with_traceback(tb)
--> 693 raise value
694 finally:
695 value = None
/usr/local/lib/python3.6/dist-packages/chainer/training/trainer.py in run(self, show_loop_exception_msg)
313 self.observation = {}
314 with reporter.scope(self.observation):
--> 315 update()
316 for name, entry in extensions:
317 if entry.trigger(self):
/usr/local/lib/python3.6/dist-packages/chainer/training/updaters/standard_updater.py in update(self)
163
164 """
--> 165 self.update_core()
166 self.iteration += 1
167
/usr/local/lib/python3.6/dist-packages/chainer/training/updaters/standard_updater.py in update_core(self)
175
176 if isinstance(in_arrays, tuple):
--> 177 optimizer.update(loss_func, *in_arrays)
178 elif isinstance(in_arrays, dict):
179 optimizer.update(loss_func, **in_arrays)
/usr/local/lib/python3.6/dist-packages/chainer/optimizer.py in update(self, lossfun, *args, **kwds)
678 if lossfun is not None:
679 use_cleargrads = getattr(self, '_use_cleargrads', True)
--> 680 loss = lossfun(*args, **kwds)
681 if use_cleargrads:
682 self.target.cleargrads()
/usr/local/lib/python3.6/dist-packages/chainer/link.py in __call__(self, *args, **kwargs)
240 if forward is None:
241 forward = self.forward
--> 242 out = forward(*args, **kwargs)
243
244 # Call forward_postprocess hook
/usr/local/lib/python3.6/dist-packages/chainer/links/model/classifier.py in forward(self, *args, **kwargs)
141 self.accuracy = None
142
--> 143 self.y = self.predictor(*args, **kwargs)
144 self.loss = self.lossfun(self.y, t)
145 reporter.report({'loss': self.loss}, self)
/usr/local/lib/python3.6/dist-packages/chainer/link.py in __call__(self, *args, **kwargs)
240 if forward is None:
241 forward = self.forward
--> 242 out = forward(*args, **kwargs)
243
244 # Call forward_postprocess hook
<ipython-input-34-89fc8be176b0> in forward(self, x)
9
10 def forward(self, x):
---> 11 h1 = F.tanh(self.l1(x))
12 h2 = F.tanh(self.l2(x))
13 y = self.l3(h3)
/usr/local/lib/python3.6/dist-packages/chainer/link.py in __call__(self, *args, **kwargs)
240 if forward is None:
241 forward = self.forward
--> 242 out = forward(*args, **kwargs)
243
244 # Call forward_postprocess hook
/usr/local/lib/python3.6/dist-packages/chainer/links/connection/linear.py in forward(self, x, n_batch_axes)
136 in_size = functools.reduce(operator.mul, x.shape[1:], 1)
137 self._initialize_params(in_size)
--> 138 return linear.linear(x, self.W, self.b, n_batch_axes=n_batch_axes)
/usr/local/lib/python3.6/dist-packages/chainer/functions/connection/linear.py in linear(x, W, b, n_batch_axes)
287 args = x, W, b
288
--> 289 y, = LinearFunction().apply(args)
290 if n_batch_axes > 1:
291 y = y.reshape(batch_shape + (-1,))
/usr/local/lib/python3.6/dist-packages/chainer/function_node.py in apply(self, inputs)
243
244 if configuration.config.type_check:
--> 245 self._check_data_type_forward(in_data)
246
247 hooks = chainer.get_function_hooks()
/usr/local/lib/python3.6/dist-packages/chainer/function_node.py in _check_data_type_forward(self, in_data)
328 in_type = type_check.get_types(in_data, 'in_types', False)
329 with type_check.get_function_check_context(self):
--> 330 self.check_type_forward(in_type)
331
332 def check_type_forward(self, in_types):
/usr/local/lib/python3.6/dist-packages/chainer/functions/connection/linear.py in check_type_forward(self, in_types)
25 x_type.ndim == 2,
26 w_type.ndim == 2,
---> 27 x_type.shape[1] == w_type.shape[1],
28 )
29 if type_check.eval(n_in) == 3:
/usr/local/lib/python3.6/dist-packages/chainer/utils/type_check.py in expect(*bool_exprs)
544 for expr in bool_exprs:
545 assert isinstance(expr, Testable)
--> 546 expr.expect()
547
548
/usr/local/lib/python3.6/dist-packages/chainer/utils/type_check.py in expect(self)
481 raise InvalidType(
482 '{0} {1} {2}'.format(self.lhs, self.exp, self.rhs),
--> 483 '{0} {1} {2}'.format(left, self.inv, right))
484
485
InvalidType:
Invalid operation is performed in: LinearFunction (Forward)
Expect: x.shape[1] == W.shape[1]
Actual: 784 != 748
3つのバグを修正し終わると、MLP3Wrongは先ほどのMLP3と一致するはずです。
課題¶
- 上記モデルをデバッグして、正しいモデルに修正しましょう。
自分のモデルを作ってみよう¶
それではみなさんが試行錯誤して、モデルを改善する時間です。モデルを自分で変更してさらに高い精度を目指してみましょう。
エポック数を増やして時間をかけるのは単純過ぎる解決策なので、エポック数10以下、かつ訓練時間100秒以内という制限の中で、テスト用データにおいて88%を超える精度を達成してみてください。おすすめの方法としては、1つ1つのパラメータを変更してみて、その効果を確かめるのが良いでしょう。
例えば、モデルの変更可能なオプションは以下があるでしょう。
- 各ユニットのノード数を増やす
- レイヤー数を増やす
- 異なる活性化関数を用いる
[ ]:
## Let's create new Multi-Layer Perceptron (MLP)
class MLPNew(Chain):
def __init__(self):
# Add more layers?
super(MLPNew, self).__init__()
with self.init_scope():
self.l1=L.Linear(784, 200) # Increase output node as (784, 300)?
self.l2=L.Linear(200, 200) # Increase nodes as (300, 300)?
self.l3=L.Linear(200, 10) # Increase nodes as (300, 10)?
def forward(self, x):
h1 = F.tanh(self.l1(x)) # Replace F.tanh with F.sigmoid or F.relu ?
h2 = F.tanh(self.l2(h1)) # Replace F.tanh with F.sigmoid or F.relu ?
y = self.l3(h2)
return y
学習方法の変更可能なオプションは以下があるでしょう。
- エポック数を増やす
- ミニバッチサイズを増やす/減らす
- Optimizerを変更する
[ ]:
device = 0
n_epoch = 5 # Add more epochs?
batchsize = 256 # Increse/Decrese mini-batch size?
model = MLPNew()
classifier_model = L.Classifier(model)
optimizer = optimizers.SGD() # Use other optimizer, Adam()?
訓練と検証を行って、まずは検証用データで目標の性能を達成する確認しましょう。
[38]:
train_and_validate(
classifier_model, optimizer, train, validation, n_epoch, batchsize, device)
epoch main/loss main/accuracy val/main/loss val/main/accuracy elapsed_time
1 1.42289 0.6079 1.00502 0.685449 2.79266
2 0.869166 0.723978 0.793229 0.736914 6.00819
3 0.729092 0.761138 0.702507 0.759766 9.38148
4 0.65631 0.781908 0.646941 0.778906 12.627
5 0.610279 0.794491 0.610744 0.79082 15.8941
損失や精度を可視化することで目標を達成できそうかも確認できます。
例えば、「検証用データの精度val/main/accuracyが順調に上昇していれば目標を達成できそう」「検証用データの精度val/main/accuracyが早い段階で頭打ちになっているからこれだと無理だ」などです。
[39]:
show_loss_and_accuracy()
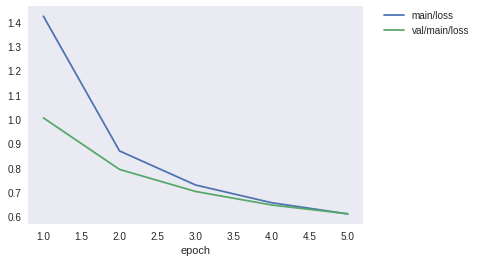
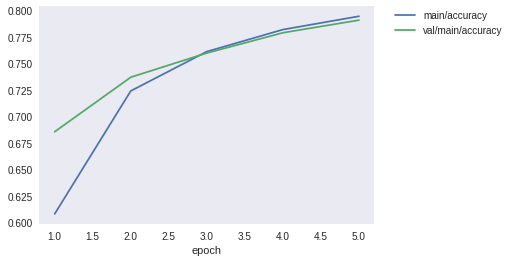
検証用データで達成したことを確認できたら、以下を実行してテスト用データでの性能を確認しましょう。
どうでしょうか、テスト用データでも目標を達成できたでしょうか。
[40]:
show_test_performance(classifier_model, test, device)
Test accuracy: 0.79160154
計算グラフを表示することで、想定通りのモデルが定義されているか確認することができます。
[41]:
show_graph()
[42]:
show_examples(model, test, device)

課題¶
LeNet5シンプルにしたモデルを以下に示します。このモデルは、3つの畳み込み(convolution)層と、2つの全結合層を持つ計5層のネットワークです。
- これを元に以下の条件で精度90%以上を達成しましょう。
- エポック数30以下
- 訓練時間200秒以内
![LeNet-5 architecture as published in [1]](https://cdn-images-1.medium.com/max/2000/1*1TI1aGBZ4dybR6__DI9dzA.png) LeNet-5 architecture as published in [1]
LeNet-5 architecture as published in [1]
[ ]:
class LeNet5(Chain):
def __init__(self):
super(LeNet5, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(
in_channels=1, out_channels=6, ksize=5, stride=1, pad=0)
self.conv2 = L.Convolution2D(
in_channels=6, out_channels=16, ksize=5, stride=1, pad=0)
self.conv3 = L.Convolution2D(
in_channels=16, out_channels=120, ksize=4, stride=1, pad=0)
self.fc4 = L.Linear(None, 84)
self.fc5 = L.Linear(84, 10)
def forward(self, x):
h = F.sigmoid(self.conv1(x.reshape((-1, 1, 28, 28))))
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.sigmoid(self.conv2(h))
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.sigmoid(self.conv3(h))
h = F.sigmoid(self.fc4(h))
return self.fc5(h)
[46]:
device = 0
n_epoch = 10
batchsize = 256
model = LeNet5()
classifier_model = L.Classifier(model)
optimizer = optimizers.Adam()
train_and_validate(
classifier_model, optimizer, train, validation, n_epoch, batchsize, device)
epoch main/loss main/accuracy val/main/loss val/main/accuracy elapsed_time
1 1.80625 0.373804 1.12389 0.588574 5.65612
2 0.942868 0.659475 0.85025 0.682227 9.75414
3 0.769315 0.714163 0.738463 0.723926 13.83
4 0.683007 0.739517 0.673598 0.73623 17.9709
5 0.62956 0.755849 0.628138 0.749512 22.2731
6 0.589923 0.769932 0.593453 0.762695 26.4592
7 0.557722 0.783084 0.575211 0.778125 30.6071
8 0.534707 0.790946 0.542991 0.783203 34.7369
9 0.511933 0.800601 0.527513 0.791504 38.85
10 0.493088 0.80971 0.509843 0.801367 42.9831
[47]:
show_graph()
[48]:
show_loss_and_accuracy()
[50]:
show_test_performance(classifier_model, test, device)
Test accuracy: 0.8044922
[51]:
show_examples(model, test, device)

課題¶
- 上記の課題では、まだ説明していないものを使っています。下記の言葉がどのような意味か調べて、説明を書いてみましょう。
- 畳み込み(convolution)層
- プーリング(pooling)層
- チャネル(channel)
次回のハンズオンでは、この課題の復習から始めようと思いますので、楽しみにしていてください。