ChainerRL で atari のゲームを DQN で解かしてみる¶
このNotebookは初めてChainerRL で atari のゲームを DQN で解かしてみるサンプルです。
|凡例|| |–|| |❔|参考になるメモです。|
以下のコマンドを実行してChainerRLをインストールします。
[3]:
!apt-get -qq -y update
# Install Chainer and CuPy!
!curl https://colab.chainer.org/install | sh -# Install ChainerRL and OpenAI Gym
!apt-get -qq -y install xvfb freeglut3-dev ffmpeg cmake swig zlib1g-dev> /dev/null
!pip -q install chainerrl atari-py gym 'gym[atari]' 'gym[box2d]' pyglet pyopengl pyvirtualdisplay
Extracting templates from packages: 100%
Google ドライブにデータを保存する準備。¶
atari のゲームを DQNで学習させると、とても時間がかかります。そのため、Google drive に経過を保存できるように、マウントしておきましょう。(参考)
❔Colaboratory は、12時間を超えて継続できません。また、90分アイドルが続くと、ランタイムは解放されます。その他の制限は、こちらが詳しいです。
次のコードセルをを実行し、以下の手順で Google アカウントの認証を行います。
- URLが表示されるのでそれをクリック
- Google アカウントにログイン
- 表示されるトークンをコピー
- このノートに戻って、テキストボックスにそのトークンを貼り付け
- 再度URLが表示されるのでそれをクリック
- このノートに戻って、テキストボックスにそのトークンを貼り付け
[ ]:
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools > /dev/null
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse > /dev/null
from google.colab import auth
auth.authenticate_user()
# Generate creds for the Drive FUSE library.
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret}
!mkdir -p drive
!google-drive-ocamlfuse drive
環境の準備¶
まず、必要なモジュールをインポートする必要があります。 ChainerRLのモジュール名は chainerrlです。 ale というのは、Arcade Learning Environmentで、Atari 2600 のゲームの環境です。
[ ]:
import chainer
from chainer import functions as F
from chainer import links as L
import chainerrl
from chainerrl.envs import ale
import numpy as np
では、環境を作ります。
Quickstartであった通り、ChainerRLは OpenAI Gym のサブセットが環境として使用可能です。
ここでは、breakout を試してみましょう。breakoutは、ブロック崩しです。こちらでゲームの様子を見ることができます。
chainerrl.experiments.prepare_output_dir ではログ出力のディレクトリを設定します。
ale.ALEで環境を作ります。学習用の環境と、バリデーション用の環境を作ります。
また、学習用の環境は、報酬を -1〜1の範囲にクリップするため、chainerrl.misc.env_modifiers.make_reward_clippedを呼び出します。
[ ]:
outdir = chainerrl.experiments.prepare_output_dir(None, "drive/dqn_out")
ROM = "breakout"
TRAIN_SEED = 0
TEST_SEED = 2 ** 16 - 1 - TRAIN_SEED
env = ale.ALE(ROM, use_sdl=False, seed=TRAIN_SEED)
chainerrl.misc.env_modifiers.make_reward_clipped(env, -1, 1)
eval_env = ale.ALE(ROM, use_sdl=False,
treat_life_lost_as_terminal=False,
seed=TEST_SEED)
n_actions = env.number_of_actions
次にQ関数、Optimizerを作ります。ここでは、Nature版の論文に掲載されていたモデルを作ります。
chainerrl.links.NatureDQNHead()で末尾のFCレイヤー以外のモデルが作成されます。
Optimizer も、Nature版の論文と同じものを設定しています。
[4]:
q_func = chainerrl.links.Sequence(
chainerrl.links.NatureDQNHead(),
L.Linear(512, n_actions),
chainerrl.action_value.DiscreteActionValue)
# Use the same hyper parameters as the Nature paper's
optimizer = chainer.optimizers.RMSpropGraves(lr=2.5e-4, alpha=0.95, momentum=0.0, eps=1e-2)
optimizer.setup(q_func)
[4]:
<chainer.optimizers.rmsprop_graves.RMSpropGraves at 0x7fc3ac7ba438>
次に、Experience reply の為のバッファーを作成と、探索を行うための Explorer を作成します。
[ ]:
rbuf = chainerrl.replay_buffer.ReplayBuffer(10 ** 6)
explorer = chainerrl.explorers.LinearDecayEpsilonGreedy(
1.0, 0.1,
10 ** 6,
lambda: np.random.randint(n_actions))
# In testing DQN, randomly select 5% of actions
eval_explorer = chainerrl.explorers.ConstantEpsilonGreedy(5e-2, lambda: np.random.randint(n_actions))
そして、Agent を作成します。
[ ]:
def dqn_phi(screens):
assert len(screens) == 4
assert screens[0].dtype == np.uint8
raw_values = np.asarray(screens, dtype=np.float32)
# [0,255] -> [0, 1]
raw_values /= 255.0
return raw_values
agent = chainerrl.agents.DQN(q_func, optimizer, rbuf, gpu=0, gamma=0.99,
explorer=explorer, replay_start_size=5 * 10 ** 4,
target_update_interval=10 ** 4,
clip_delta=True,
update_interval=4,
batch_accumulator='sum', phi=dqn_phi)
学習¶
では、学習を開始してみましょう。これは、10時間ほどかかります。
その間、Colaboratoryのウインドウを閉じないように、またPCがサスペンドにならないように注意してください。
[ ]:
import sys
STEPS = 10 ** 7
def step_hook(env, agent, step):
sys.stdout.write("\r{} / {} steps.".format(step, STEPS))
sys.stdout.flush()
chainerrl.experiments.train_agent_with_evaluation(
agent=agent, env=env, steps=STEPS,
eval_n_runs=10, eval_interval=10 ** 5,
outdir=outdir, eval_explorer=eval_explorer,
eval_env=eval_env, step_hooks=[step_hook])
モデルの再ロード¶
学習が終わった後、暫く放置しているなどで、Runtimeが切れているかもしれないので、ここで再ロードをしておきます。
以下で、drive/dqn_out/ 以下の最新の model.npz を探します。
[ ]:
import pandas as pd
import glob
import os
model_files = glob.glob("drive/dqn_out/*/*/model.npz")
model_files.sort(key=os.path.getmtime)
last_model_dir = os.path.dirname(model_files[-1])
last_model_dir
'drive/dqn_out/20180401T130507.493354/10_finish'
そして、Agent を作成し、ロードします。
[ ]:
import chainer
from chainer import functions as F
from chainer import links as L
import chainerrl
from chainerrl.envs import ale
import numpy as np
ROM = "breakout"
TRAIN_SEED = 0
TEST_SEED = 2 ** 16 - 1 - TRAIN_SEED
env = ale.ALE(ROM, use_sdl=False, seed=TRAIN_SEED)
chainerrl.misc.env_modifiers.make_reward_clipped(env, -1, 1)
eval_env = ale.ALE(ROM, use_sdl=False,
treat_life_lost_as_terminal=False,
seed=TEST_SEED)
n_actions = env.number_of_actions
q_func = chainerrl.links.Sequence(
chainerrl.links.NatureDQNHead(),
L.Linear(512, n_actions),
chainerrl.action_value.DiscreteActionValue)
# Use the same hyper parameters as the Nature paper's
optimizer = chainer.optimizers.RMSpropGraves(lr=2.5e-4, alpha=0.95, momentum=0.0, eps=1e-2)
optimizer.setup(q_func)
rbuf = chainerrl.replay_buffer.ReplayBuffer(10 ** 6)
explorer = chainerrl.explorers.LinearDecayEpsilonGreedy(
1.0, 0.1,
10 ** 6,
lambda: np.random.randint(n_actions))
def dqn_phi(screens):
assert len(screens) == 4
assert screens[0].dtype == np.uint8
raw_values = np.asarray(screens, dtype=np.float32)
# [0,255] -> [0, 1]
raw_values /= 255.0
return raw_values
agent = chainerrl.agents.DQN(q_func, optimizer, rbuf, gpu=0, gamma=0.99,
explorer=explorer, replay_start_size=5 * 10 ** 4,
target_update_interval=10 ** 4,
clip_delta=True,
update_interval=4,
batch_accumulator='sum', phi=dqn_phi)
agent.load(last_model_dir)
学習結果の確認¶
「drive/dqn_out」 以下には、学習を開始した時刻でディレクトリが作成されています。
その中に、scores.txt が格納されているので、見てみましょう。mean、median等は、報酬の値の平均、中央値等示しています。
[ ]:
import pandas as pd
import glob
import os
score_files = glob.glob("drive/dqn_out/*/scores.txt")
score_files.sort(key=os.path.getmtime)
score_file = score_files[-1]
df = pd.read_csv(score_file, delimiter='\t' )
df
| steps | episodes | elapsed | mean | median | stdev | max | min | average_q | average_loss | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100019 | 2530 | 723.888525 | 2.7 | 0.0 | 4.347413 | 9.0 | 0.0 | 0.303997 | 0.150887 |
| 1 | 200069 | 5118 | 1658.790631 | 2.3 | 0.0 | 4.595892 | 11.0 | 0.0 | 0.338333 | 0.140443 |
| 2 | 300023 | 7698 | 2574.870919 | 3.6 | 2.0 | 3.864367 | 9.0 | 0.0 | 0.285880 | 0.077487 |
| 3 | 400034 | 10366 | 3497.920046 | 1.0 | 1.0 | 1.247219 | 4.0 | 0.0 | 0.310269 | 0.066922 |
| 4 | 500052 | 12999 | 4411.688253 | 3.4 | 3.0 | 1.173788 | 5.0 | 2.0 | 0.543558 | 0.084011 |
| 5 | 600004 | 15279 | 5314.304720 | 2.8 | 3.0 | 0.788811 | 4.0 | 1.0 | 0.667274 | 0.099451 |
| 6 | 700081 | 17123 | 6216.525888 | 4.7 | 5.0 | 1.159502 | 6.0 | 3.0 | 0.928593 | 0.161979 |
| 7 | 800057 | 18436 | 7138.914733 | 11.7 | 10.5 | 4.448470 | 19.0 | 7.0 | 0.863669 | 0.172142 |
| 8 | 900006 | 19416 | 8060.686812 | 18.9 | 19.0 | 5.839521 | 29.0 | 10.0 | 1.021046 | 0.209086 |
| 9 | 1000218 | 20234 | 8967.935466 | 19.3 | 17.0 | 8.781926 | 39.0 | 11.0 | 1.487955 | 0.275206 |
| 10 | 1100057 | 21008 | 9865.520058 | 16.5 | 15.5 | 6.293736 | 24.0 | 6.0 | 1.556474 | 0.271245 |
| 11 | 1200022 | 21736 | 10764.720788 | 21.0 | 20.0 | 6.879922 | 34.0 | 14.0 | 1.567833 | 0.304757 |
| 12 | 1300033 | 22405 | 11648.578367 | 23.1 | 23.0 | 8.582281 | 39.0 | 12.0 | 1.505138 | 0.331790 |
| 13 | 1400177 | 22989 | 12557.847888 | 40.8 | 44.0 | 14.482173 | 59.0 | 12.0 | 1.318606 | 0.319410 |
| 14 | 1500000 | 23532 | 13455.470889 | 37.6 | 40.0 | 11.625642 | 54.0 | 21.0 | 1.802185 | 0.346138 |
| 15 | 1600031 | 24049 | 14366.151622 | 36.1 | 32.0 | 12.609080 | 60.0 | 24.0 | 2.110291 | 0.306692 |
| 16 | 1700331 | 24506 | 15303.498786 | 64.8 | 66.5 | 13.587576 | 87.0 | 46.0 | 1.982212 | 0.544427 |
| 17 | 1800250 | 24948 | 16270.881940 | 45.0 | 40.0 | 23.069942 | 85.0 | 16.0 | 1.903823 | 0.355040 |
| 18 | 1900024 | 25375 | 17232.791353 | 61.8 | 61.5 | 17.955501 | 94.0 | 30.0 | 2.220175 | 0.368105 |
| 19 | 2000189 | 25792 | 18196.678026 | 55.9 | 51.5 | 19.980268 | 85.0 | 24.0 | 2.339100 | 0.404514 |
| 20 | 2100205 | 26171 | 19171.657341 | 63.6 | 64.0 | 11.983322 | 82.0 | 43.0 | 1.917374 | 0.348760 |
| 21 | 2200071 | 26560 | 20139.300665 | 84.5 | 80.5 | 12.258784 | 113.0 | 73.0 | 2.400482 | 0.353057 |
| 22 | 2300241 | 26942 | 21124.147876 | 97.1 | 79.5 | 55.967153 | 254.0 | 65.0 | 2.394080 | 0.430013 |
| 23 | 2400477 | 27312 | 22094.673264 | 110.7 | 82.0 | 61.508897 | 214.0 | 46.0 | 2.905017 | 0.350502 |
| 24 | 2500219 | 27689 | 23054.687035 | 60.9 | 58.5 | 17.791696 | 93.0 | 36.0 | 2.748551 | 0.414613 |
| 25 | 2600183 | 28056 | 24010.998144 | 77.3 | 62.5 | 39.631777 | 145.0 | 28.0 | 2.831579 | 0.466401 |
| 26 | 2700182 | 28417 | 24972.797742 | 105.7 | 95.5 | 36.917476 | 193.0 | 73.0 | 2.872277 | 0.423788 |
| 27 | 2800000 | 28786 | 25897.783444 | 110.4 | 89.0 | 55.670060 | 251.0 | 65.0 | 3.647376 | 0.471424 |
| 28 | 2900080 | 29135 | 26864.933631 | 176.3 | 162.5 | 69.439102 | 324.0 | 94.0 | 4.812175 | 0.490252 |
| 29 | 3000000 | 29473 | 27839.079186 | 208.6 | 223.0 | 71.300927 | 315.0 | 100.0 | 7.419030 | 0.498739 |
| 30 | 3100030 | 29822 | 28747.818277 | 141.1 | 102.0 | 80.219768 | 261.0 | 55.0 | 4.245854 | 0.737231 |
| 31 | 3200143 | 30157 | 29673.194213 | 193.9 | 188.5 | 58.616361 | 281.0 | 97.0 | 3.741049 | 0.725786 |
| 32 | 3300281 | 30493 | 30614.941162 | 181.2 | 198.5 | 69.256047 | 288.0 | 28.0 | 4.800403 | 0.562647 |
| 33 | 3400029 | 30834 | 31557.831995 | 235.4 | 240.5 | 49.788888 | 298.0 | 135.0 | 4.435642 | 0.731802 |
| 34 | 3500312 | 31169 | 32521.849709 | 250.9 | 249.5 | 39.646914 | 313.0 | 189.0 | 5.550049 | 0.685425 |
| 35 | 3600069 | 31507 | 33507.644210 | 249.2 | 250.0 | 47.585712 | 336.0 | 191.0 | 6.160767 | 0.882242 |
| 36 | 3700212 | 31839 | 34497.500384 | 209.2 | 211.5 | 61.775220 | 290.0 | 107.0 | 4.605931 | 0.728111 |
[ ]:
df[["max", "median", "mean", "stdev", "min"]].plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7fc6d9c4deb8>
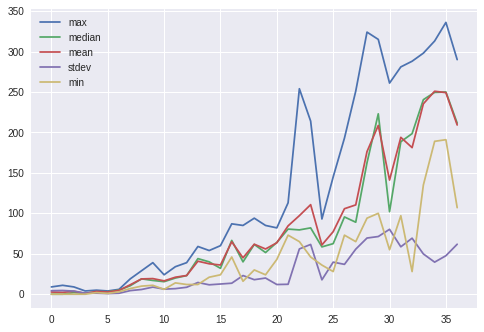
エピソードを重ねる毎に、報酬が増えていることが分かります。
実行結果の確認¶
chainerrl.env.ale には、render()が無かったので、ale の getScreenRGB() を使って、結果を確認します。
以下で、frames に画面を格納します。
[ ]:
frames = []
for i in range(10):
obs = env.reset()
done = False
R = 0
t = 0
while not done:
action = agent.act(obs)
obs, r, done, _ = env.step(action)
frames.append(env.ale.getScreenRGB())
R += r
t += 1
print('test episode:', i, 'R:', R)
agent.stop_episode()
以下で、アニメーションを作成します。
[ ]:
import matplotlib.pyplot as plt
import matplotlib.animation
import numpy as np
from IPython.display import HTML
fig = plt.figure(figsize=(5, 5))
plt.axis('off')
images = []
for f in frames:
image = plt.imshow(f)
images.append([image])
ani = matplotlib.animation.ArtistAnimation(fig, images, interval=30, repeat_delay=1)
HTML(ani.to_jshtml())

まだ学習時間が不十分なようですが、ある程度、プレイできるようになっているのが確認できるかと思います。