01 Chainerの基本的な使い方を学んでみよう¶
このNotebookの目的は以下の通りです。
- 畳み込みニューラルネットワークについて学習すること
- 過学習・汎化性能を理解すること
- Chainerの機能について学習すること
ColaboratoryでChainerを使うための設定¶
必要なライブラリ・Chainer・CuPyのインストール¶
下記のスクリプト内では、GPUを動かすのに必要なパッケージのインストール、Chainerのインストール、cudaのバージョンに応じたCuPyのインストールが行われています。
本来なら適切なバージョンのCuPyをインストールする必要があります。しかし、上記スクリプトはColaboratoryにインストールされているcudaのバージョンを見て、自動的に適切なCuPyをインストールします。
[ ]:
!curl https://colab.chainer.org/install | sh -
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1580 100 1580 0 0 3615 0 --:--:-- --:--:-- --:--:-- 3607
+ apt -y -q install cuda-libraries-dev-10-0
Reading package lists...
Building dependency tree...
Reading state information...
cuda-libraries-dev-10-0 is already the newest version (10.0.130-1).
0 upgraded, 0 newly installed, 0 to remove and 8 not upgraded.
+ pip install -q cupy-cuda100 chainer
+ set +ex
Installation succeeded!
Chainer v4.0.0からchainer.print_runtime_info()という便利なメソッドが追加されました。以下のコマンドをターミナルで実行し、ChainerやCuPyが正しくインストールされたかを確認してみましょう。
[ ]:
!python -c 'import chainer; chainer.print_runtime_info()'
Platform: Linux-4.14.79+-x86_64-with-Ubuntu-18.04-bionic
Chainer: 5.0.0
NumPy: 1.14.6
CuPy:
CuPy Version : 5.2.0
CUDA Root : /usr/local/cuda
CUDA Build Version : 10000
CUDA Driver Version : 10000
CUDA Runtime Version : 10000
cuDNN Build Version : 7301
cuDNN Version : 7301
NCCL Build Version : 2307
iDeep: 2.0.0.post3
うまくインストールできていますね。以下のチュートリアルでは、pydotをネットワーク構造の可視化に使いますので、これも同時にインストールしておきましょう。
[ ]:
!apt -y -qq install graphviz > /dev/null 2> /dev/null
!pip install pydot
Requirement already satisfied: pydot in /usr/local/lib/python3.6/dist-packages (1.3.0)
Requirement already satisfied: pyparsing>=2.1.4 in /usr/local/lib/python3.6/dist-packages (from pydot) (2.3.1)
最後に以前使用した関数をchutilというパッケージにまとめましたので、ここでインストールしましょう。
[ ]:
!pip install chutil
Collecting chutil
Downloading https://files.pythonhosted.org/packages/74/d3/e761e43572a1bc53ab787a11b227b9ccc0e857cdb531805fb12e4e15707a/chutil-0.1.4-py3-none-any.whl
Installing collected packages: chutil
Successfully installed chutil-0.1.4
[ ]:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import chainer
import chutil
畳み込みニューラルネットワーク (前回の復習)¶
LeNet5をシンプルにしたモデルを以下に示します。このモデルは、3つの畳み込み(convolution)層と、2つの全結合層を持つ計5層のネットワークです。
- これを元に以下の条件で精度90%以上を達成しましょう。
- エポック数30以下
- 訓練時間200秒以内
![LeNet-5 architecture as published in [1]](https://cdn-images-1.medium.com/max/2000/1*1TI1aGBZ4dybR6__DI9dzA.png) LeNet-5 architecture as published in [1]
LeNet-5 architecture as published in [1]
class LeNet5(Chain):
def __init__(self):
super(LeNet5, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(
in_channels=1, out_channels=6, ksize=5, stride=1, pad=0)
self.conv2 = L.Convolution2D(
in_channels=6, out_channels=16, ksize=5, stride=1, pad=0)
self.conv3 = L.Convolution2D(
in_channels=16, out_channels=120, ksize=4, stride=1, pad=0)
self.fc4 = L.Linear(None, 84)
self.fc5 = L.Linear(84, 10)
def __call__(self, x):
h = F.sigmoid(self.conv1(x.reshape((-1, 1, 28, 28))))
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.sigmoid(self.conv2(h))
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.sigmoid(self.conv3(h))
h = F.sigmoid(self.fc4(h))
return self.fc5(h)
そもそも、ここでは初めて紹介することになる層があると思います。まずはこれらについて説明します。
- 畳み込み層 (
L.Convolution2D) - プーリング層 (
F.max_pooling_2d)
2次元畳み込み層 (L.Convolution2D)¶
畳み込み層とは、入力データに対して畳み込み演算を行う層のことです。今回は画像に適用するということで、特に2次元の場合について説明します。
畳み込み層に使用される主なパラメータとして、以下が存在します。
- フィルターサイズ
ksize:フィルターの長さのこと - ストライド
stride:フィルターの適用間隔のこと - パッディングサイズ
pad:周辺を0で埋める長さのこと
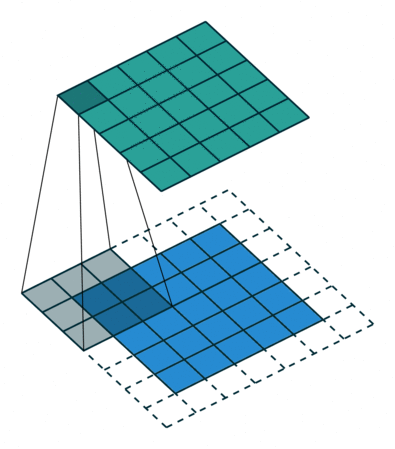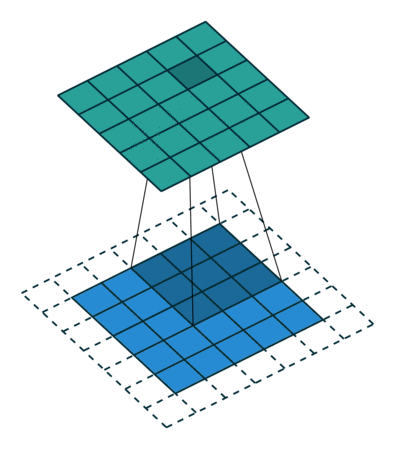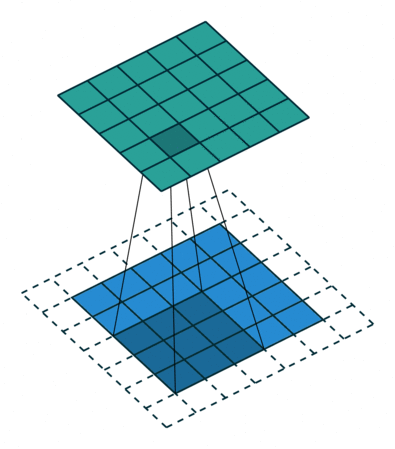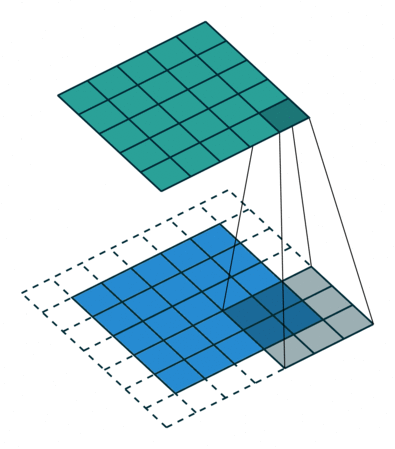
言葉で説明するよりは画像を利用したほうが直感的に理解できると思うので、 例えば以下の場合についてgif画像[2]を利用して説明します。
- フィルターサイズ
ksize=3、ストライドstride=1、パッディングサイズpad=0 - フィルターサイズ
ksize=3、ストライドstride=2、パッディングサイズpad=0 - フィルターサイズ
ksize=3、ストライドstride=1、パッディングサイズpad=1
1についてですが、フィルターサイズ ksize=3とあるように、平行移動しているフィルターの長さが3になっています。
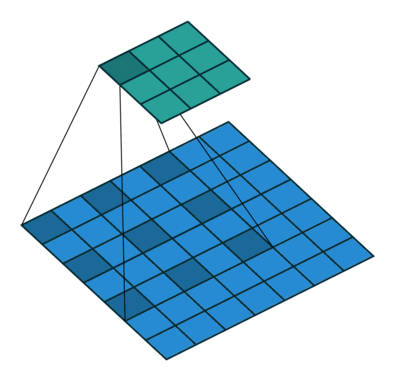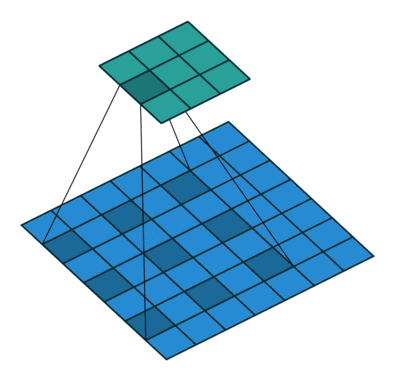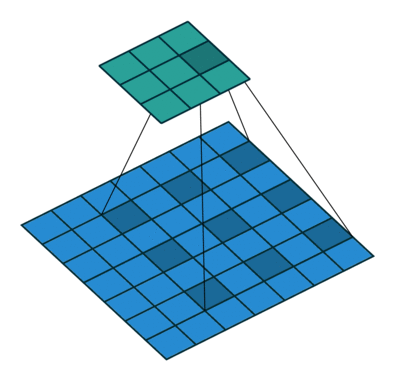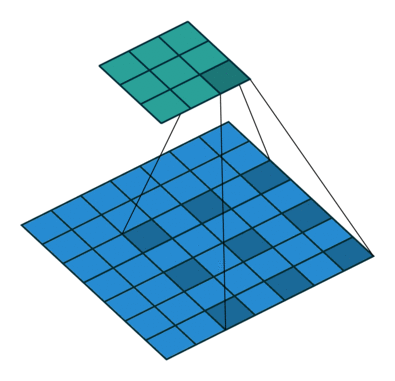
2についてですが、1に対してストライド stride=2と変化しています。そのため、フィルターの長さに変化はありませんが、入力データに対して2個おきにフィルターを適用しています。
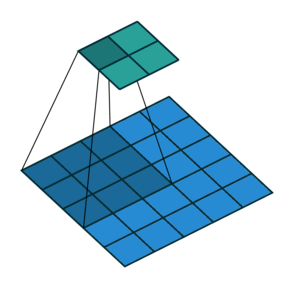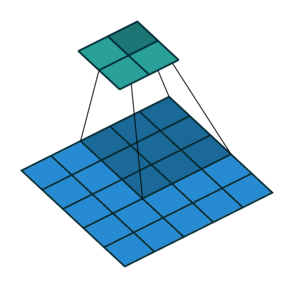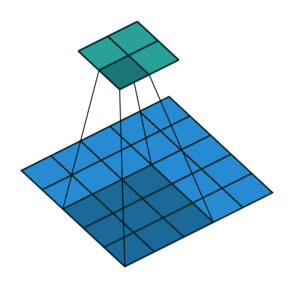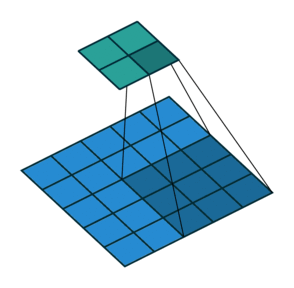
3についてですが、1に対してパッディングサイズ pad=1と変化しています。そのため、フィルターの長さに変化はありませんが、周囲を1つ穴埋めした入力データに対してフィルターを適用しています。
おそらくお気づきになったと思いますが、上記のパラメータによって入力データと出力データのサイズが変化します。入力データのサイズを\(L_i\)、出力データのサイズを\(L_o\)とした時以下の関係があります。
そもそもなぜこのような畳み込み処理を画像に適用するのでしょうか。
実は画像処理では、古くから畳み込み処理により平滑化やエッジ抽出を行ってきました。 例えば、ラプラシアンフィルタは以下のようにエッジ抽出の効果があります。

もし、フィルターサイズ ksize=3のフィルタが以下だった場合、
畳み込み層も同様の役割を持つでしょう。
WikipediaのKernel_(image_processing)の項目には、他のフィルターも紹介されていますので御覧ください。
課題¶
- 上記のパラメータ以外にも、
dilateというパラメータがあります。以下のように、飛び飛びにフィルターを適用します。この時、入力データのサイズ𝐿𝑖 と出力データのサイズ𝐿𝑜の間で、どのような等式が成り立つでしょうか。
プーリング層 (F.max_pooling_2d)¶
プーリング層は、ダウンサンプルを行う層です。こちらも画像の場合なので、特に2次元の場合を説明します。
プーリング層も、畳み込み層と同様のパラメータを持ちます。
- フィルターサイズ
ksize:フィルターの長さのこと - ストライド
stride:フィルターの適用間隔のこと - パッディングサイズ
pad:周辺を0で埋める長さのこと
F.max_pooling_2dの場合、フィルター適用範囲の最大値を結果として出力します。
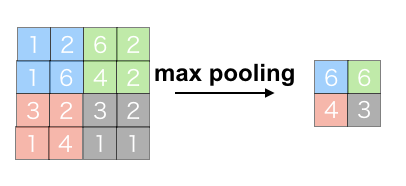
他のプーリング層はReferenceを参照ください。
前回の課題に挑戦¶
前回の繰り返しにはなりますが、データセットのダウンロードと、訓練のための関数train_and_validateを定義します。
[ ]:
from chainer.datasets.fashion_mnist import get_fashion_mnist
# データセットがダウンロード済みでなければ、ダウンロードも行う
train, test = get_fashion_mnist(withlabel=True, ndim=1)
train, validation = chainer.datasets.split_dataset_random(train, 50000, seed=0)
Downloading from http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz...
Downloading from http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz...
Downloading from http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz...
Downloading from http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz...
[ ]:
from chainer import optimizers, training
from chainer.training import extensions
def train_and_validate(
model, optimizer, train, validation, n_epoch, batchsize, device=0):
# 1. deviceがgpuであれば、gpuにモデルのデータを転送する
if device >= 0:
model.to_gpu(device)
# 2. Optimizerを設定する
optimizer.setup(model)
# 3. DatasetからIteratorを作成する
train_iter = chainer.iterators.SerialIterator(train, batchsize)
validation_iter = chainer.iterators.SerialIterator(
validation, batchsize, repeat=False, shuffle=False)
# 4. Updater・Trainerを作成する
updater = training.StandardUpdater(train_iter, optimizer, device=device)
trainer = chainer.training.Trainer(updater, (n_epoch, 'epoch'), out='out')
# 5. Trainerの機能を拡張する
trainer.extend(extensions.LogReport())
trainer.extend(extensions.Evaluator(validation_iter, model, device=device), name='val')
trainer.extend(extensions.PrintReport(
['epoch', 'main/loss', 'main/accuracy', 'val/main/loss', 'val/main/accuracy', 'elapsed_time']))
trainer.extend(extensions.PlotReport(
['main/loss', 'val/main/loss'],x_key='epoch', file_name='loss.png'))
trainer.extend(extensions.PlotReport(
['main/accuracy', 'val/main/accuracy'], x_key='epoch', file_name='accuracy.png'))
trainer.extend(extensions.dump_graph('main/loss'))
# 6. 訓練を開始する
trainer.run()
それでは、LeNet5にいくつかの変更を加えたMyConvNetを定義して、訓練とテストを行ってみましょう。変更点はコメントにあるように以下の通りです。
- 各convolution層のチャネル数、ノード数を増やす
- 各convolution層のフィルター数
ksize=3, ストライドstride=3、パッディングpad=1に変更 - convolution層を1層(
conv4)追加 - 活性化関数を
ReLUに変更
ちなみに、L.Convolution2Dのin_channelsやL.Linearの第一引数をNoneにすることで明示的にサイズを指定していませんが、実はこれでもちゃんと動きます。なぜかというと、最初のforward呼び出し時に、入力されたサイズで動的にメモリを確保してくれるからです。Chainerの良さの1つですね。
[ ]:
import chainer.functions as F
import chainer.links as L
from chainer import Chain
class MyConvNet(Chain):
def __init__(self):
super(MyConvNet, self).__init__()
with self.init_scope():
# all pads are 0 -> 1
self.conv1 = L.Convolution2D(
in_channels=None, out_channels=32, ksize=3, stride=1, pad=1) # 6 -> 32
self.conv2 = L.Convolution2D(
in_channels=None, out_channels=64, ksize=3, stride=1, pad=1) # 16 -> 64
self.conv3 = L.Convolution2D(
in_channels=None, out_channels=128, ksize=3, stride=1, pad=1) # 120 -> 128
self.conv4 = L.Convolution2D(
in_channels=None, out_channels=128, ksize=3, stride=1, pad=1) # new layer
self.fc5 = L.Linear(None, 1000) # 84 -> 1000
self.fc6 = L.Linear(None, 10)
def forward(self, x):
h = F.relu(self.conv1(x.reshape((-1, 1, 28, 28))))
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.relu(self.conv2(h)) # sigmoid -> relu
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.relu(self.conv3(h)) # sigmoid -> relu
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.relu(self.conv4(h)) # sigmoid -> relu
h = F.relu(self.fc5(h)) # sigmoid -> relu
return self.fc6(h)
ここで、このようなモデルにしたのには理由があります。画像の分野で有名なモデルは多くありますが、その中の1つにVGG16があります。今回は以下のような点を倣ってみました。
- chennelを32 -> 64 -> 128というようにだんだんと増やしていく。
ksize=3, stride=1, pad=1にする
特に、ksize=3, stride=1, pad=1にする理由は明確にあり、これを上記等式に代入すると、
以下が成立します。こうすることによって、入力データと出力データのサイズが等しくなり、取扱いが楽になります。
では、上記変更を加えたモデルMyConvNetを訓練してみましょう。
[ ]:
n_epoch = 20
batchsize = 128
model = MyConvNet()
classifier_model = L.Classifier(model)
optimizer = optimizers.Adam()
train_and_validate(
classifier_model, optimizer, train, validation, n_epoch, batchsize)
epoch main/loss main/accuracy val/main/loss val/main/accuracy elapsed_time
1 0.470625 0.826726 0.332186 0.874604 15.6066
2 0.279406 0.898018 0.268071 0.901206 22.583
3 0.233507 0.914143 0.244181 0.91248 29.5549
4 0.1988 0.925651 0.238763 0.911887 36.5105
5 0.17286 0.935522 0.258228 0.908623 43.482
6 0.150243 0.943449 0.233626 0.920886 50.4599
7 0.127471 0.952206 0.240237 0.916139 57.4998
8 0.113513 0.95641 0.245398 0.918315 64.4619
9 0.0938525 0.964654 0.301464 0.914656 71.4548
10 0.081645 0.969449 0.274138 0.919996 78.4565
11 0.0720359 0.972596 0.292828 0.914755 85.4173
12 0.0613123 0.976622 0.33783 0.918809 92.4091
13 0.0536207 0.979699 0.370851 0.918908 99.3976
14 0.0450274 0.983694 0.337244 0.920293 106.355
15 0.0421986 0.984815 0.367212 0.917425 113.337
16 0.0388388 0.985176 0.362449 0.915744 120.371
17 0.0332791 0.987492 0.406139 0.917524 127.35
18 0.0285132 0.98943 0.403559 0.919304 134.351
19 0.0295068 0.989944 0.460843 0.920194 141.332
20 0.0335374 0.988791 0.465256 0.914557 148.318
検証用データでも90%の精度を達成しています。これならテスト用データでも目標を達成してそうですね。
以下の関数を実行して確かめてみましょう。
[ ]:
from chutil.visualize.show import show_test_performance
show_test_performance(classifier_model, test)
Test accuracy: 0.9152344
達成できていましたね!パチパチ!
と終わりにしたいところですが、もう少し細かく結果を見てみましょう。
まずは、show_graphを使ってネットワーク構造を表示してみましょう。 実際にどのようなネットワークができたか確認できますね。
[ ]:
from chutil.visualize.show import show_graph
show_graph()

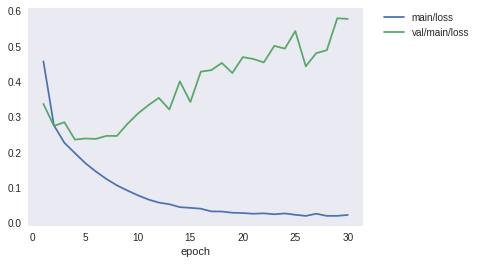
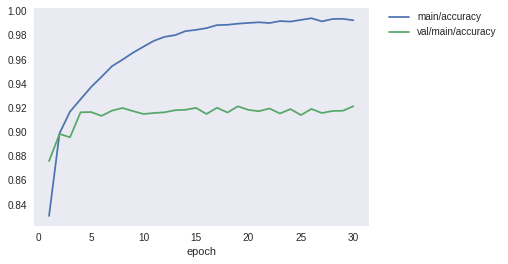
次に、show_loss_and_accuracyを使って、訓練用データと検証用データの損失と精度をplotしてみましょう。 おそらく以下のことに気づくと思います。
- 訓練用データでは、
epoch数に伴い、損失は減少・精度は増加し、共に改善している - しかし、検証用データでは、
epoch=5程度で精度は頭打ちになっており、損失も最小値になったあと悪化している
[ ]:
from chutil.visualize.show import show_loss_and_accuracy
show_loss_and_accuracy()
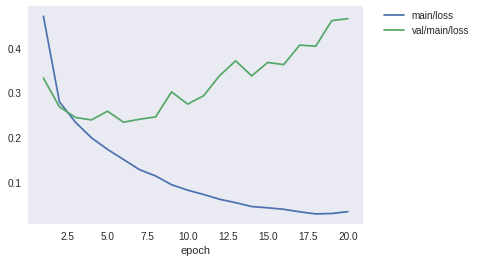
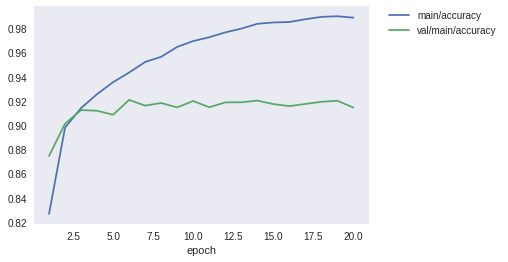
訓練用データでは精度が順調に伸びるのに、検証用データでは伸びない・・・。このような現象をどこかで聞いたことがあるような気がしますよね。
過学習と汎化性能¶
過学習とは¶
上記のように、訓練用データに対して精度が高いが、未知データ(訓練には使用していないデータ)に対しては精度が低い、という現象を過学習と呼びます。
過学習が起きてしまう原因は様々にありますが、概して以下が挙げられると思います。
- 訓練用データと、未知のデータの性質が異なる
- 訓練用データに対して学習をしすぎ、結果に対して偽陽性な関連性について学習をしてしまっている
前回、試験問題の例えを使って、簡単に過学習について説明しましたが、その例えをここでも使うと以下のように言えます。
- 練習問題を解いてきたが、試験では全く違う分野の問題が出てきてしまい解けなかった
- 練習問題を解きすぎて答えを丸暗記してしまい、試験ではその覚えた答えを使ってそのまま解答したら微妙な違いがあって不正解だった
ちなみに、機械学習において過学習が起きてしまう場合、以下のようなことをしている場合が多いです。
- 解きたい問題に対して、データ数が少なすぎる
- 解きたい問題に対して、モデルが複雑すぎる
また、Deep Learningの場合、適切なepoch数で訓練を切り上げることをしないと、多くの場合過学習を引き起こしてしまいます。例えば、さきほど訓練したモデルで、検証用データの精度・損失のグラフを見ると、5epoch目あたりの精度が最も高そうです。
このように、Deep Learningは訓練をし続けると最終的には過学習してしまいます。しかし、以下の場合は性能を改善するために、過学習を防ぐ手法を試してみる価値はあります。
- 検証用データの精度・損失を見ると、少ないepoch数で既に過学習が始まっている
- 検証用データの精度・損失が想定に達していない
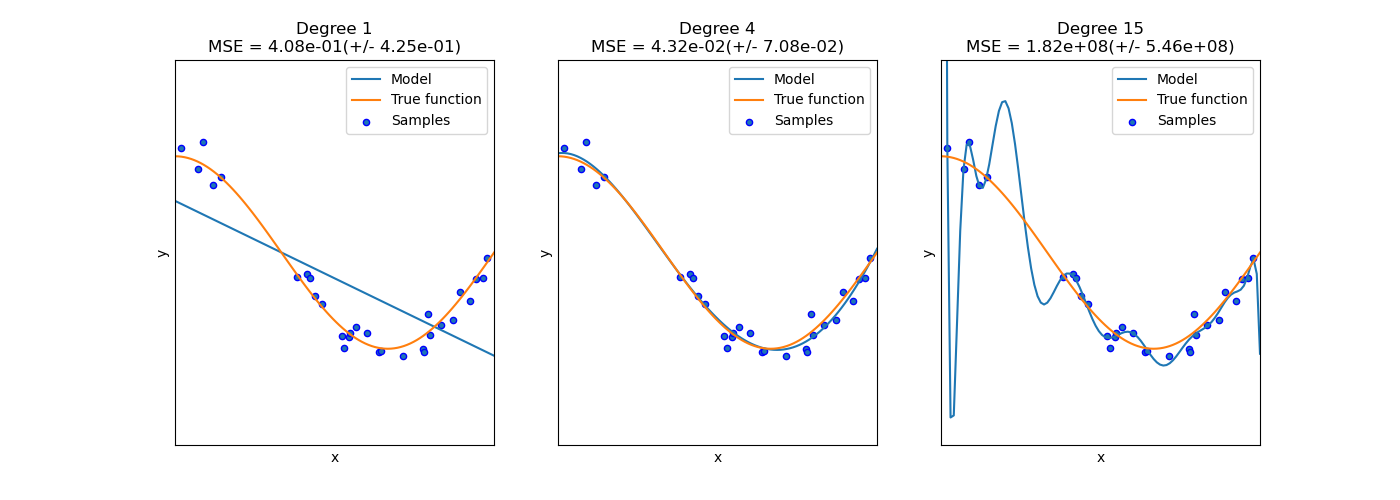
課題¶
scikit-learnの Underfitting vs Overfitting は、「Overfitting (過学習)」と「Underfitting (過学習の対義語)」を説明したwebページです。これを実行してみて、モデルが複雑すぎるとなぜ過学習してしまうのか、体験してみてください。
汎化性能とは¶
そもそも過学習というのは、どのような状況を意味しているのでしょうか。ここでは違う観点から説明を行いたいと思います。
度々説明していますが、汎化性能とは未知データに対する予測性能のことを言います。この性能を最大化するのが、私たちのゴールです。あらゆる関数の中から最も汎化性能の高い関数を選べたとして、その関数を以下の図で\(f^*\)とします。
また、ある訓練結果の予測関数を\(f\)とします。例えば、私たちが今回作り出した学習結果が該当します。
誤差の種類¶
実は最終的なゴールである\(f^*\)と、私たちが作り出した関数\(f\)の間には大きく分けて3つの誤差が存在します。
ここで、\(F\)はあるモデルが表現できる範囲を意味し、例えば今回の話で言うと上記のNNが表現できる関数の範囲になります。それなので、\(f^*_F\)は、そのモデルで表現できる範囲で最も汎化性能の高い関数となります。
また、\(f^*_F\)を求めようにも与えられたデータに限りがある場合は正しく求められません。有限のデータを与えられた時に求められる関数を\(\hat{f}_F\)と表現します。
この時、それぞれの誤差を以下のように言います。
- 近似誤差
- モデルの表現力を反映する誤差
- 推定誤差
- 訓練用データが実際に使用するときのデータと異なることによって生まれる誤差
- 過学習の原因
- 最適化誤差
- 数値計算誤差などによって生まれる、訓練用データの最適な関数との誤差
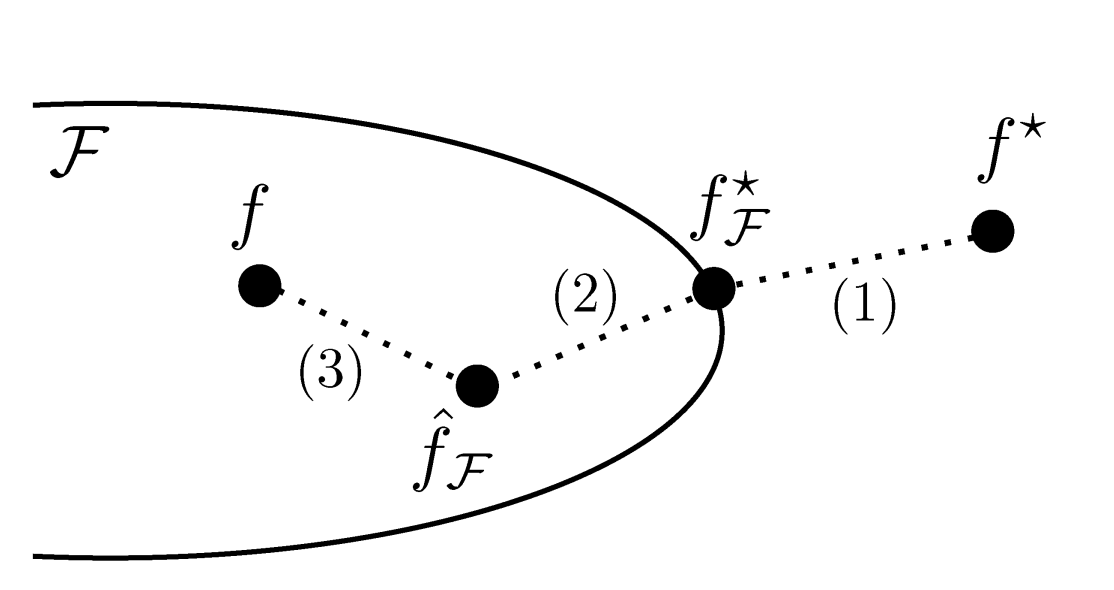
cited from [3]
過学習は2の誤差が大きい状況を言います。Deep Learningは層を積み重ねるなどネットワークを複雑にすることで\(F\)の範囲を大きくし(1)の誤差を小さくします。そして、大量のデータを用いることで(2)の誤差を小さくすることで求められる関数\(f\)をできるだけ\(f^*\)に近づけます。
Dropout¶
ここで、NNで汎化性能の改善に効くと言われているDropoutという手法を使ってみましょう。Dropoutは学習時、推論時に以下を行います。
- 学習時:一定の確率\(p\)で入力を0にし(無視する)、その分残りを\(\frac{1}{1-p}\)倍にして出力する
- 推論時:何もしない
同時に複数のモデルを学習し、その結果をアンサンブル学習したような効果が生まれ、結果として汎化性能が改善されることがあります。
課題¶
- 下記コードにDropoutを追加して効果を確かめてみましょう。Dropoutの追加やパラメータの変更をすることで精度93%以上を達成しましょう。
h = F.dropout(F.relu(self.fc5(h))) # add dropout
Droopoutの追加は上記のようにすることでできます。
[ ]:
class MyConvNet(Chain):
def __init__(self):
super(MyConvNet, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(
in_channels=None, out_channels=32, ksize=3, stride=1, pad=1)
self.conv2 = L.Convolution2D(
in_channels=None, out_channels=64, ksize=3, stride=1, pad=1)
self.conv3 = L.Convolution2D(
in_channels=None, out_channels=128, ksize=3, stride=1, pad=1)
self.conv4 = L.Convolution2D(
in_channels=None, out_channels=128, ksize=3, stride=1, pad=1)
self.fc5 = L.Linear(None, 1000)
self.fc6 = L.Linear(None, 10)
def forward(self, x):
h = F.relu(self.conv1(x.reshape((-1, 1, 28, 28))))
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.relu(self.conv2(h))
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.relu(self.conv3(h))
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.relu(self.conv4(h))
h = F.relu(self.fc5(h))
return self.fc6(h)
[ ]:
n_epoch = 30
batchsize = 128
model = MyConvNet()
classifier_model = L.Classifier(model)
optimizer = optimizers.Adam()
train_and_validate(
classifier_model, optimizer, train, validation, n_epoch, batchsize)
epoch main/loss main/accuracy val/main/loss val/main/accuracy elapsed_time
1 0.456109 0.830643 0.335562 0.875989 6.63569
2 0.274964 0.898957 0.273486 0.898438 13.6215
3 0.225512 0.916927 0.283768 0.895669 20.606
4 0.196383 0.92709 0.234679 0.916337 27.61
5 0.167761 0.93716 0.237751 0.916535 34.5833
6 0.144232 0.945693 0.236612 0.91337 41.5768
7 0.123174 0.954484 0.24515 0.917722 48.6362
8 0.105159 0.959876 0.245012 0.919897 55.6073
9 0.090544 0.965613 0.278993 0.917326 62.563
10 0.0769669 0.970648 0.308274 0.914953 69.5125
11 0.0650284 0.975481 0.331948 0.915744 76.5066
12 0.0563735 0.97874 0.352752 0.916337 83.4925
13 0.051693 0.980139 0.319769 0.918018 90.4489
14 0.0434744 0.983474 0.399553 0.918414 97.4057
15 0.0414642 0.984515 0.341075 0.919996 104.38
16 0.0390966 0.985937 0.426999 0.914953 111.315
17 0.0314338 0.988451 0.431212 0.920095 118.389
18 0.0310831 0.988711 0.451568 0.916139 125.376
19 0.0276358 0.989623 0.423088 0.921282 132.363
20 0.0267285 0.990249 0.468159 0.918315 139.344
21 0.0248198 0.990789 0.462794 0.917227 146.326
22 0.0259587 0.990144 0.453061 0.919502 153.309
23 0.0232741 0.991788 0.499928 0.915348 160.278
24 0.0256837 0.991366 0.492148 0.919007 167.205
25 0.0218215 0.992747 0.541743 0.914062 174.197
26 0.0186409 0.994126 0.442056 0.919106 181.176
27 0.024832 0.991526 0.479478 0.915744 188.153
28 0.0187659 0.993486 0.487616 0.917425 195.133
29 0.0187599 0.993646 0.578133 0.917623 202.217
30 0.0213809 0.992408 0.576137 0.921381 209.209
[ ]:
show_loss_and_accuracy()
[ ]:
show_test_performance(classifier_model, test)
Test accuracy: 0.9160156
ちなみに下記のようなモデルを動かしてみると93%前後の性能が実現できました。
class MyConvNet(Chain):
def __init__(self):
super(MyConvNet, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(
in_channels=None, out_channels=32, ksize=3, stride=1, pad=1)
self.conv2 = L.Convolution2D(
in_channels=None, out_channels=64, ksize=3, stride=1, pad=1)
self.conv3 = L.Convolution2D(
in_channels=None, out_channels=128, ksize=3, stride=1, pad=1)
self.conv4 = L.Convolution2D(
in_channels=None, out_channels=128, ksize=3, stride=1, pad=1)
self.fc5 = L.Linear(None, 2000) # 1000 -> 2000
self.fc6 = L.Linear(None, 10)
def __call__(self, x):
h = F.dropout(F.relu(self.conv1(x.reshape((-1, 1, 28, 28)))), ratio=0.2) # add dropout
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.dropout(F.relu(self.conv2(h)), ratio=0.2) # add dropout
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.dropout(F.relu(self.conv3(h)), ratio=0.2) # add dropout
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.dropout(F.relu(self.conv4(h))) # add dropout
h = F.dropout(F.relu(self.fc5(h))) # add dropout
return self.fc6(h)
課題¶
他にも汎化性能の向上に効く手法としてNomalization(正則化)という手法があります。
Chainerには多くのメジャーな正則化手法が揃っています。それぞれどのような正則化をしているか調べ、実際に使ってみてください。
Chainerの機能¶
前回、今回のハンズオンでは、下記の関数train_and_validateを使用してきました。 ここでは、その関数の中身について解説していきます。
def train_and_validate(
model, optimizer, train, validation, n_epoch, batchsize, device=0):
# 1. deviceがgpuであれば、gpuにモデルのデータを転送する
if device >= 0:
model.to_gpu(device)
# 2. Optimizerを設定する
optimizer.setup(model)
# 3. DatasetからIteratorを作成する
train_iter = chainer.iterators.SerialIterator(train, batchsize)
validation_iter = chainer.iterators.SerialIterator(
validation, batchsize, repeat=False, shuffle=False)
# 4. Updater・Trainerを作成する
updater = training.StandardUpdater(train_iter, optimizer, device=device)
trainer = chainer.training.Trainer(updater, (n_epoch, 'epoch'), out='out')
# 5. Trainerの機能を拡張する
trainer.extend(extensions.LogReport())
trainer.extend(extensions.Evaluator(validation_iter, model, device=device), name='val')
trainer.extend(extensions.PrintReport(
['epoch', 'main/loss', 'main/accuracy', 'val/main/loss', 'val/main/accuracy', 'elapsed_time']))
trainer.extend(extensions.PlotReport(
['main/loss', 'val/main/loss'],x_key='epoch', file_name='loss.png'))
trainer.extend(extensions.PlotReport(
['main/accuracy', 'val/main/accuracy'], x_key='epoch', file_name='accuracy.png'))
trainer.extend(extensions.dump_graph('main/loss'))
# 6. 訓練を開始する
trainer.run()
1. cpu/gpuを決める¶
Chainerの各関数にはdeviceという引数を渡す関数が多く存在します。それに-1を与えるとcpuで動作し、0以上の値を指定すると、そのIDのGPUを使用することになります。
2. 最適化手法の選択¶
学習時に用いる最適化の手法としてはいろいろな種類のものが提案されていますが、Chainerは多くの手法を同一のインターフェースで利用できるよう、Optimizerという機能でそれらを提供しています。chainer.optimizersモジュール以下に色々なものを見つけることができます。一覧はこちらにあります:
Optimizerのオブジェクトには、setupメソッドを使ってモデル(Chainオブジェクト)を渡します。こうすることでOptimizerに、何を最適化すればいいか把握させることができます。
他にもいろいろな最適化手法が手軽に試せるので、色々と試してみて結果の変化を見てみてください。例えば、chainer.optimizers.SGDのうちSGDの部分をMomentumSGD, RMSprop, Adamなどに変えるだけで、最適化手法の違いがどのような学習曲線(ロスカーブ)の違いを生むかなどを簡単に調べることができます。
NOTE¶
Optimizerのコンストラクタにはlrという引数があります。この値は学習率として知られ、モデルをうまく訓練して良いパフォーマンスを発揮させるために調整する必要がある重要なハイパーパラメータとして知られています。

3. Iteratorの作成¶
データセットはが、このままネットワークの学習に使うのは少し面倒です。なぜなら、ネットワークのパラメータ最適化手法として広く用いられているStochastic Gradient Descent (SGD)という手法では、一般的にいくつかのデータを束ねた ミニバッチ と呼ばれる単位でネットワークにデータを渡し、それに対する予測を作って、ラベルと比較するということを行います。そのため、バッチサイズ分だけデータとラベルを束ねる作業が必要です。
そこで、データセットから決まった数のデータとラベルを取得し、それらを束ねてミニバッチを作ってくれる機能を持ったIteratorを使いましょう。 Iteratorは、先程作ったデータセットオブジェクトを渡して初期化してやったあとは、next()メソッドで新しいミニバッチを返してくれます。内部ではデータセットを何周なめたか(epoch)などの情報が記録されており、学習ループを書いていく際に便利です。
train_iter = chainer.iterators.SerialIterator(train, batchsize)
validation_iter = chainer.iterators.SerialIterator(
validation, batchsize, repeat=False, shuffle=False)
ここでは、学習に用いるデータセット用のイテレータ(train_iter)と、検証用のデータセット用のイテレータ(validation_iter)、の計2つを作成しています。ここで、batchsize = 128だったとすると、作成した2つのIteratorは、例えばtrain_iter.next()などとすると128枚の数字画像データを一括りにして返してくれます。
NOTE: SerialIteratorについて¶
Chainerがいくつか用意しているIteratorの一種であるSerialIteratorは、データセットの中のデータを順番に取り出してくる最もシンプルなIteratorです。コンストラクタの引数にデータセットオブジェクトと、バッチサイズを取ります。このとき、渡したデータセットオブジェクトから、何周も何周もデータを繰り返し読み出す必要がある場合はrepeat引数をTrueとし、1周が終わったらそれ以上データを取り出したくない場合はこれをFalseとします。これは、主にvalidation用のデータセットに対して使うフラグです。デフォルトでは、Trueになっています。また、shuffle引数にTrueを渡すと、データセットから取り出されてくるデータの順番をエポックごとにランダムに変更します。SerialIteratorの他にも、マルチプロセスで高速にデータを処理できるようにしたMultiprocessIteratorやMultithreadIteratorなど、複数のIteratorが用意されています。詳しくは以下を見てください。
4-1. Updaterの準備¶
ここからが学習ループを自分で書く場合と異なる部分です。ループを自分で書く場合には、データセットからバッチサイズ分のデータをとってきてミニバッチに束ねて、それをネットワークに入力して予測を作り、それを正解と比較し、ロスを計算してバックワード(誤差逆伝播)をして、Optimizerによってパラメータを更新する、というところまでを、以下のように書いていました。
# ---------- 学習の1イテレーション ----------
train_batch = train_iter.next()
x, t = concat_examples(train_batch, gpu_id)
# 予測値の計算
y = net(x)
# ロスの計算
loss = F.softmax_cross_entropy(y, t)
# 勾配の計算
net.cleargrads()
loss.backward()
# パラメータの更新
optimizer.update()
これらの処理を、まるっとUpdaterはまとめてくれます。これを行うために、UpdaterにはIteratorとOptimizerを渡してやります。
Iteratorはデータセットオブジェクトを持っていて、そこからミニバッチを作り、Optimizerは最適化対象のネットワークを持っていて、それを使って前進計算とロスの計算・パラメータのアップデートをすることができます。そのため、この2つを渡しておけば、上記の処理をUpdater内で全部行ってもらえるというわけです。では、Updaterオブジェクトを作成してみましょう。
NOTE¶
モデルを定義するときに、ネットワークをL.Classifierで包んでいます。L.Classifierは一種のChainになっていて、渡されたネットワーク自体をpredictorというattributeに持ち、ロス計算を行う機能を追加してくれます。 こうすると、net()はデータxだけでなくラベルtも取るようになり、まず渡されたデータをpredictorに通して予測を作り、それをtと比較してロスのVariableを返すようになります。
ロス関数として何を用いるかはデフォルトではF.softmax_cross_entropyとなっていますが、L.Classifierの引数lossfuncにロス計算を行う関数を渡してやれば変更することができるため、Classifierという名前ながら回帰問題などのロス計算機能の追加にも使うことができます。(L.Classifier(net, lossfun=L.mean_squared_error, compute_accuracy=False)のようにする)
StandardUpdaterは前述のようなUpdaterの担当する処理を遂行するための最もシンプルなクラスです。この他にも複数のGPUを用いるためのParallelUpdaterなどが用意されています。
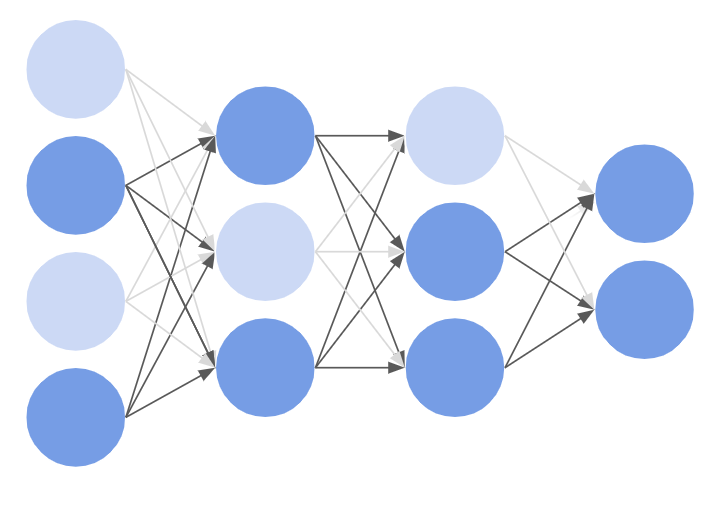
4-2. Trainerの準備¶
実際に学習ループ部分を隠蔽しているのはUpdaterなので、これがあればもう学習を始められそうですが、TrainerはさらにUpdaterを受け取って学習全体の管理を行う機能を提供しています。例えば、データセットを何周したら学習を終了するか(stop_trigger) や、途中のロスの値をどのファイルに保存したいか、ロスカーブを可視化した画像ファイルを保存するかどうかなど、学習全体の設定として必須・もしくはあると便利な色々な機能を提供しています。
必須なものとしては学習終了のタイミングを指定するstop_triggerがありますが、これはTrainerオブジェクトを作成するときのコンストラクタで指定します。指定の方法は単純で、(長さ, 単位)という形のタプルを与えればよいだけです。「長さ」には数字を、「単位」には'iteration'もしくは'epoch'のいずれかの文字列を指定します。こうすると、たとえば100 epoch(データセット100周)で学習を終了してください、とか、1000
iteration(1000回更新)で学習を終了してください、といったことが指定できます。Trainerを作るときに、stop_triggerを指定しないと、学習は自動的には止まりません。
では、実際にTrainerオブジェクトを作ってみましょう。
out引数では、この次に説明するExtensionを使って、ログファイルやロスの変化の過程を描画したグラフの画像ファイルなどを保存するディレクトリを指定しています。
Trainerと、その内側にあるいろいろなオブジェクトの関係は、図にまとめると以下のようになっています。このイメージを持っておくと自分で部分的に改造したりする際に便利だと思います。

5. TrainerにExtensionを追加する¶
Trainerを使う利点として、
- ログを自動的にファイルに保存(
LogReport) - ターミナルに定期的にロスなどの情報を表示(
PrintReport) - ロスを定期的にグラフで可視化して画像として保存(
PlotReport) - 定期的にモデルやOptimizerの状態を自動シリアライズ(
snapshot) - 学習の進捗を示すプログレスバーを表示(
ProgressBar) - ネットワークの構造をGraphvizのdot形式で保存(
dump_graph) - ネットワークのパラメータの平均や分散などの統計情報を出力(
ParameterStatistics)
などなどの様々な便利な機能を簡単に利用することができる点があります。これらの機能を利用するには、Trainerオブジェクトに対してextendメソッドを使って追加したいExtensionのオブジェクトを渡してやるだけです。では実際に幾つかのExtensionを追加してみましょう。
LogReport¶
epochやiterationごとのloss, accuracyなどを自動的に集計し、Trainerのout引数で指定した出力ディレクトリにlogというファイル名で保存します。
snapshot¶
Trainerのout引数で指定した出力ディレクトリにTrainerオブジェクトを指定されたタイミング(デフォルトでは1エポックごと)に保存します。Trainerオブジェクトは上述のようにUpdaterを持っており、この中にOptimizerとモデルが保持されているため、このExtensionでスナップショットをとっておけば、学習の復帰や学習済みモデルを使った推論などが学習終了後にも可能になります。
dump_graph¶
指定されたVariableオブジェクトから辿れる計算グラフをGraphvizのdot形式で保存します。保存先はTrainerのout引数で指定した出力ディレクトリです。
Evaluator¶
評価用のデータセットのIteratorと、学習に使うモデルのオブジェクトを渡しておくことで、学習中のモデルを指定されたタイミングで評価用データセットを用いて評価します。内部では、chainer.config.using_config('train', False)が自動的に行われます。backprop_enableをFalseにすることは行われないため、メモリ使用効率はデフォルトでは最適ではありませんが、基本的にはEvaluatorを使えば評価を行うという点において問題はありません。
PrintReport¶
Reporterによって集計された値を標準出力に出力します。このときどの値を出力するかを、リストの形で与えます。
PlotReport¶
引数のリストで指定された値の変遷をmatplotlibライブラリを使ってグラフに描画し、出力ディレクトリにfile_name引数で指定されたファイル名で画像として保存します。
ParameterStatistics¶
指定したレイヤ(Link)が持つパラメータの平均・分散・最小値・最大値などなどの統計情報を計算して、ログに保存します。パラメータが発散していないかなどをチェックするのに便利です。
これらのExtensionは、ここで紹介した以外にも、例えばtriggerによって個別に作動するタイミングを指定できるなどのいくつかのオプションを持っており、より柔軟に組み合わせることができます。詳しくは公式のドキュメントを見てください
課題¶
- 下記を変更してみて、Chainerの機能を体験してみましょう。
[ ]:
def my_train_and_validate(
model, optimizer, train, validation, n_epoch, batchsize, device=0):
# 1. deviceがgpuであれば、gpuにモデルのデータを転送する
if device >= 0:
model.to_gpu(device)
# 2. Optimizerを設定する
optimizer.setup(model)
# 3. DatasetからIteratorを作成する
train_iter = chainer.iterators.SerialIterator(train, batchsize)
validation_iter = chainer.iterators.SerialIterator(
validation, batchsize, repeat=False, shuffle=False)
# 4. Updater・Trainerを作成する
updater = training.StandardUpdater(train_iter, optimizer, device=device)
trainer = chainer.training.Trainer(updater, (n_epoch, 'epoch'), out='out')
# 5. Trainerの機能を拡張する
# 6. 訓練を開始する
trainer.run()
[ ]:
class MyConvNet(Chain):
def __init__(self):
super(MyConvNet, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(
in_channels=None, out_channels=32, ksize=3, stride=1, pad=1)
self.conv2 = L.Convolution2D(
in_channels=None, out_channels=64, ksize=3, stride=1, pad=1)
self.conv3 = L.Convolution2D(
in_channels=None, out_channels=128, ksize=3, stride=1, pad=1)
self.conv4 = L.Convolution2D(
in_channels=None, out_channels=128, ksize=3, stride=1, pad=1)
self.fc5 = L.Linear(None, 2000) # 1000 -> 2000
self.fc6 = L.Linear(None, 10)
def __call__(self, x):
h = F.dropout(F.relu(self.conv1(x.reshape((-1, 1, 28, 28)))), ratio=0.2) # add dropout
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.dropout(F.relu(self.conv2(h)), ratio=0.2) # add dropout
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.dropout(F.relu(self.conv3(h)), ratio=0.2) # add dropout
h = F.max_pooling_2d(h, ksize=2, stride=2)
h = F.dropout(F.relu(self.conv4(h))) # add dropout
h = F.dropout(F.relu(self.fc5(h))) # add dropout
return self.fc6(h)
[ ]:
n_epoch = 5
batchsize = 128
model = MyConvNet()
classifier_model = L.Classifier(model)
optimizer = optimizers.Adam()
my_train_and_validate(
classifier_model, optimizer, train, validation, n_epoch, batchsize)
次回の準備¶
次回のハンズオンでは自分で用意したデータセットでの学習を予定しています。その予習として下記のようなkaggleのデータセットを用意してみました。下記課題ではkaggleからデータセットのdownload、結果の提出部分を用意していますので、ぜひ自分のモデルで学習させてみてsubmitしてみてください。
次回の準備として、kaggleのデータセットを利用して何かしらの結果を提出してみましょう。手順はリンクを参考にしています。
[ ]:
!pip install kaggle
Requirement already satisfied: kaggle in /usr/local/lib/python3.6/dist-packages (1.5.2)
Requirement already satisfied: urllib3<1.23.0,>=1.15 in /usr/local/lib/python3.6/dist-packages (from kaggle) (1.22)
Requirement already satisfied: six>=1.10 in /usr/local/lib/python3.6/dist-packages (from kaggle) (1.11.0)
Requirement already satisfied: certifi in /usr/local/lib/python3.6/dist-packages (from kaggle) (2018.11.29)
Requirement already satisfied: python-dateutil in /usr/local/lib/python3.6/dist-packages (from kaggle) (2.5.3)
Requirement already satisfied: requests in /usr/local/lib/python3.6/dist-packages (from kaggle) (2.18.4)
Requirement already satisfied: tqdm in /usr/local/lib/python3.6/dist-packages (from kaggle) (4.28.1)
Requirement already satisfied: python-slugify in /usr/local/lib/python3.6/dist-packages (from kaggle) (2.0.1)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests->kaggle) (3.0.4)
Requirement already satisfied: idna<2.7,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests->kaggle) (2.6)
Requirement already satisfied: Unidecode>=0.04.16 in /usr/local/lib/python3.6/dist-packages (from python-slugify->kaggle) (1.0.23)
- https://www.kaggle.com/UserName/account で自分のアカウントページを開いてください
- 上記ページ内の Create New API Token をクリックして kaggle.json をダウンロードしてください
- https://drive.google.com/drive/my-drive を開いてください
- ドライブ上の好きな場所に kaggle.json をアップロードしてください
[ ]:
from googleapiclient.discovery import build
import io, os
from googleapiclient.http import MediaIoBaseDownload
from google.colab import auth
auth.authenticate_user()
drive_service = build('drive', 'v3')
results = drive_service.files().list(
q="name = 'kaggle.json'", fields="files(id)").execute()
kaggle_api_key = results.get('files', [])
filename = "/root/.kaggle/kaggle.json"
os.makedirs(os.path.dirname(filename), exist_ok=True)
request = drive_service.files().get_media(fileId=kaggle_api_key[0]['id'])
fh = io.FileIO(filename, 'wb')
downloader = MediaIoBaseDownload(fh, request)
done = False
while done is False:
status, done = downloader.next_chunk()
print("Download %d%%." % int(status.progress() * 100))
os.chmod(filename, 600)
Download 100%.
- digitがつくcompetitionsの検索
[ ]:
!kaggle competitions list -s digit
ref deadline category reward teamCount userHasEntered
---------------- ------------------- --------------- --------- --------- --------------
digit-recognizer 2030-01-01 00:00:00 Getting Started Knowledge 2562 True
- digit-recognizerのデータセットのダウンロード(予めコンペへの参加 (コンペルールへの同意) は済ませる必要がります)
[ ]:
!kaggle competitions download -c digit-recognizer
Downloading train.csv to /content
98% 72.0M/73.2M [00:01<00:00, 41.7MB/s]
100% 73.2M/73.2M [00:01<00:00, 65.8MB/s]
Downloading test.csv to /content
70% 34.0M/48.8M [00:00<00:00, 23.7MB/s]
100% 48.8M/48.8M [00:00<00:00, 68.7MB/s]
Downloading sample_submission.csv to /content
0% 0.00/235k [00:00<?, ?B/s]
100% 235k/235k [00:00<00:00, 30.6MB/s]
[ ]:
!ls /content/
adc.json out sample_submission.csv train.csv
graph.png sample_data test.csv
- コンペに提出
[ ]:
!kaggle competitions submit -c digit-recognizer -f /content/sample_submission.csv -m "Test"
- 上記データセットは今まで使用したネットワークを使って学習することができます。試しに学習を行い、submitしてみてください。
今まで学習していないこととしては以下があるので注意してください。
- 好きなデータから
Datasetを作ること - 結果を出力し、提出用ファイルに整形すること
Reference¶
- [1] [Gradient-based learning applied to document recognition](http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf)
- [2] [Vincent Dumoulin, Francesco Visin - A guide to convolution arithmetic for deep learning](https://arxiv.org/abs/1603.07285)
- [3] [最適化から見たディープラーニングの考え方](http://www.orsj.or.jp/archive2/or60-4/or60_4_191.pdf)
- [4] [CS231n](http://cs231n.github.io/neural-networks-3/)
[ ]: